Home
Apache JMeter is open source software, a 100% pure Java application designed to load test functional behavior and measure performance. It was originally designed for testing Web Applications but has since expanded to other test functions.
Apache JMeter may be used to test performance both on static and dynamic resources (files, Servlets, Perl scripts, Java Objects, Data Bases and Queries, FTP Servers and more). It can be used to simulate a heavy load on a server, network or object to test its strength or to analyze overall performance under different load types. You can use it to make a graphical analysis of performance or to test your server/script/object behavior under heavy concurrent load.
We have developed a Jmeter plugin to apply load to Cassandra. This plugin acts as a client of Cassandra and can send requests over either Astayanax or Thrift. The plugin is fully configurable.
It is best to create your Cassandra Jmeter experiment on a laptop or desktop. As a 100% Java application Jmeter runs on OS X, Windows and Linux. Having created the Cassandra Jmeter jar, copy it to directory lib/ext on your laptop. From the Jmeter home directory run bin/jmeter. This will bring up the initial screen

The first step is to add a Thread Group. This will determine how much load is applied to Cassandra. Load is adjusted by increasing or decreasing the number of threads in the thread group.
After creating the thread group you can confirm that the Cassandra JMeter plugin has been loaded correctly. Select the Thread Group, right click and a pull down menu will appear. Select Add, then Sampler. The 7 Cassandra Samplers should be included in the list. See the screenshot below.

The fist step in a Cassandra JMeter experiment is selecting the CassandraProperties. This defines how Jmeter will communicate with the Cassandra cluster. Again right click the Thread Group -> Add -> Config Element -> CassandraProperties. Lets walk through an example screenshot
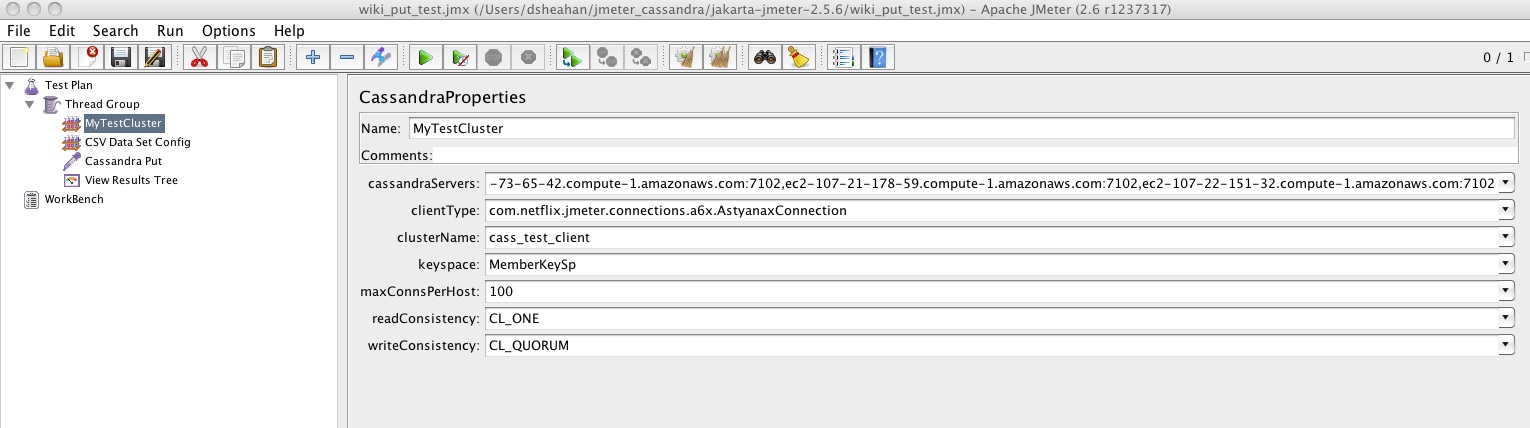
Important note - when changing the values in these fields click the downarrow button on the left and select Edit. You can then enter the required value. You cannot enter the value directly.
-
cassandraServers defines the Cassandra server names JMeter will communicate with, these can be IP addresses or fully qualified names. You need to also include the rpc_port (as defined in cassandra.yaml) on which Cassandra is listening for Thrift clients - in this example 7102. Format is server_name:port. You do not have to list all the servers in the cluster, one is the minimum requirement. This list is essentially the Cassandra co-ordinator nodes that will be used.
-
clientType defines the communication protocol, this can be Astyanax or Thrift. For Astyanax as in the example below enter com.netflix.jmeter.connections.AstyanaxConnection. For Thrift use com.netflix.jmeter.connections.thrift.ThriftConnection.
-
clusterName is the cluster name as defined by field cluster_name in the cassandra.yaml file
-
keyspace is the keyspace in the cluster to send all requests. Note this means that each thread group can only send load to a single keyspace. It can, however, send load to different Column Families within a keyspace.
-
maxConnsPerHost - for each server listed in the cassandraServers field JMeter will establish this number of connections. For example if there are 6 servers in the list and maxConnsPerHost is set to 10 then a maximum of 60 connections will be established. You can test how many have actually been established using netstat -a
-
readConsistency / writeConsistency This determines what consistency level to use for reads abd writes to the cluster.
If Astyanax is selected in clientType then Consistencies must be one of
CL_ONE Get confirmation from a single node (fastest)
CL_TWO Get confirmation from 2 nodes
CL_THREE Get confirmation from 3 nodes
CL_QUORUM Get confirmation from the majority of nodes (don't use in multiregion)
CL_EACH_QUORUM In multiregional get confirmation from quarum in each region
CL_LOCAL_QUORUM In multiregional get confirmation from quarum in current region only
CL_ALL Get confirmation from all replicas
If Thrift is selected the equivalent options are ONE, TWO, THREE, QUORUM, EACH_QUORUM, LOCAL_QUORUM, ALL
Often we want to load specific data into or get a specific row from cluster. This is achieved using a CSV file. As usual right click on Thread Group -> Add -> Config Element -> CSV Data Set Config.
See the screenshot below for an example. First we specify the filename of the data. Next the layout of this file is specified. By default fields are seperated by a comma but this can be , etc. In the example each line of the file wiki_example.csv contains a rowid and the value to place in this row.
The file wiki_example.csv must exist in the JMeter home directory. Its format would be something like
1,my_data_aaa
2,my_data_bbb
3,my_data_ccc
...
Each time the CSV Data Set is encountered in the experiment by a thread a single line will be read and two variables, ${rowid} and ${value} will be loaded. Each thread gets its own copy of these variables.
The sharing mode determines how the file is shared between threads. Recycle on EOF and Stop thread on EOF determine what to do when the file is exhausted.

Once the CassandraProperties and any potential CSV data have been setup, we are ready to start reading and writing from/to the Cassandra cluster. Let's start with Puts as these are needed to populate the cluster with data.
Using cassandra-cli on one of the cluster nodes we create a simple schema, with a Keyspace called MemberKeySp and a Column Family Customer
create keyspace MemberKeySp
with placement_strategy = 'NetworkTopologyStrategy'
and strategy_options = [{us-east : 3}]
and durable_writes = true;
use MemberKeySp;
create column family Customer
with column_type = 'Standard'
and comparator = 'UTF8Type'
and default_validation_class = 'BytesType'
and key_validation_class = 'UTF8Type'
and rows_cached = 0.0
and row_cache_save_period = 0
and keys_cached = 100000.0
and key_cache_save_period = 14400
and read_repair_chance = 0.0
and gc_grace = 864000
and min_compaction_threshold = 4
and max_compaction_threshold = 32
and replicate_on_write = false
and row_cache_provider = 'ConcurrentLinkedHashCacheProvider'
and comment = 'Customer Records';
To insert a Put into the experiment right click on Thread Group -> Add -> Sampler -> Cassandra Put
Looking at the screen shot the following fields are required for the simple Put

-
ColumnFamily specifies which column family to send the request to
-
ROW KEY specifies the row key to use. This can be a random variable, constant text or a JMeter variable, either generated by a bean shell or read from a csv file. In the example below we have used a variable ${rowid} read from the csv example above.
-
COLUMN NAME the name of the column to insert also a random, constant or JMeter variable. In the example below we have chosen a Random value
-
COLUMN VALUE the value to store for this column, random, constant or JMeter variable. In the example below we have chosen a JMeter variable ${value} read from a csv file.
-
Serializers - each field needs to define the Java serializer to use when communicating with Cassandra. Selecting the serializer is very important for correct operation. This can be one of AsciiSerializer, BooleanSerializer, DateSerializer, BytesSerializer, CharSerializer, StringSerializer, FloatSerializer, UUIDSerializer, IntegerSerializer, DoubleSerializer, ShortSerializer, LongSerializer, BigIntegerSerializer.
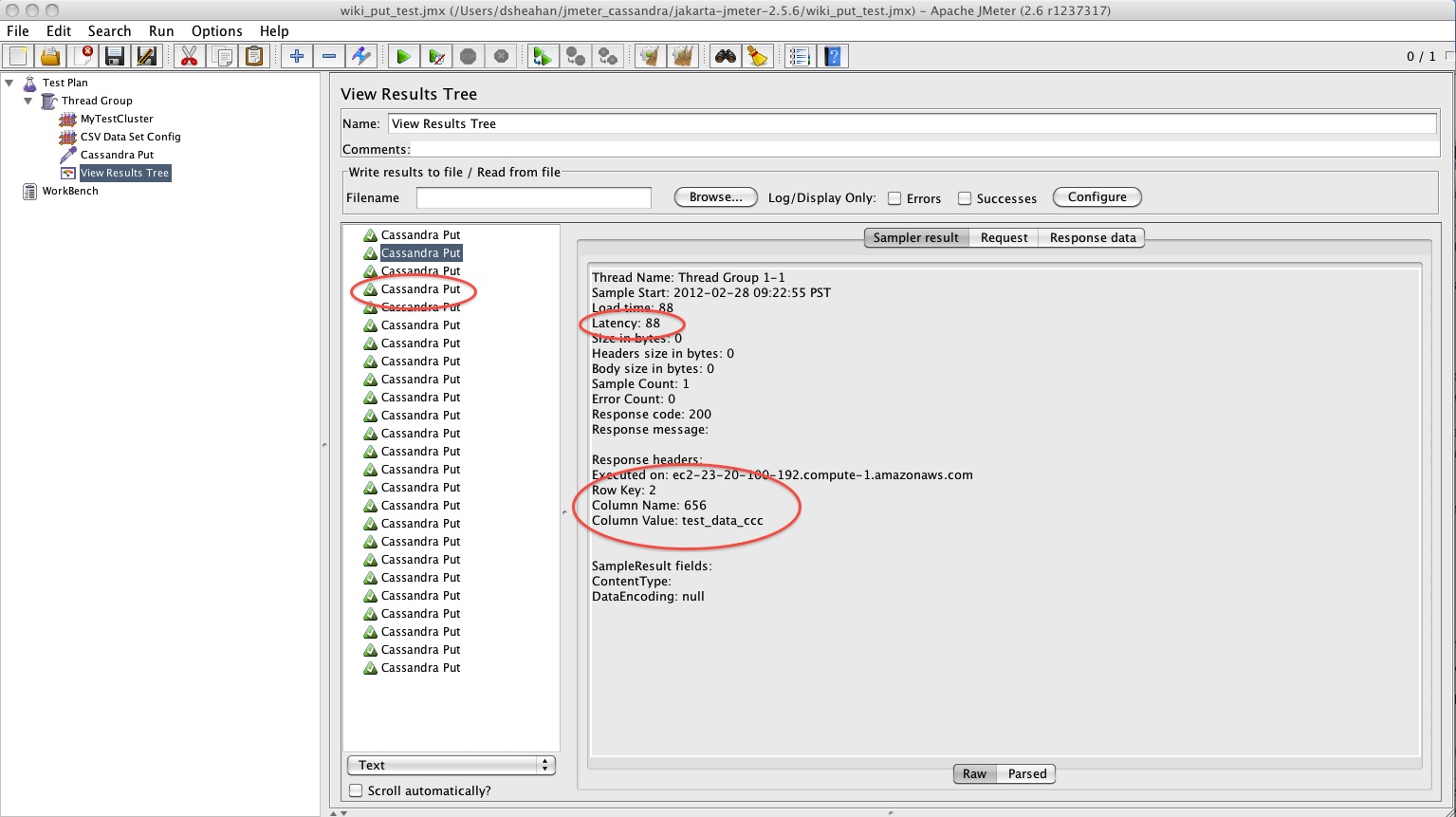
The best way to determine if your Cassandra Put has succeeded is to add a View Results Tree listener. As always right click Thread Group -> Add -> Listener -> View Results Tree
The View Results tree shows if each transaction suceeded, displayed in Green, or had an Error, displayed in Red. The result of running our Cassandra Put for a csv file with 25 entries is shown below. On the left I have highlighted the success and in the sampler result I have highlighted the Row key used for the mutation, its column name and value. Also highlighted is the latency in miliseconds for the transaction.
The results can also be dumped to a file for post processing if necessary
We can check whether the rows were inserted on the Cassandra cluster using cassandra-cli
[default@unknown] use MemberKeySp;
Authenticated to keyspace: MemberKeySp
[default@MemberKeySp] list Customer;
Using default limit of 100
-------------------
RowKey: 3
=> (column=266, value=746573745f646174615f646464, timestamp=1330034215605000)
-------------------
RowKey: 6
=> (column=59, value=746573745f646174615f676767, timestamp=1330034216403000)
-------------------
RowKey: 5
=> (column=610, value=746573745f646174615f666666, timestamp=1330034216138000)
-------------------
RowKey: 19
=> (column=924, value=746573745f646174615f747474, timestamp=1330034217553000)
If there is an error the left hand column will be highlighted in Red. In this case the Error Count in the Sampler Result will be non-zero. An indication of the failure (Usually a Java stack trace) will be thrown in the Response Data window. In the example screenshot the simple Put failed because I choose BytesArraySerializer for the Value and we got a NumberFormatException

If we want to put multiple colums in a single row we use the Batch Put Option. Right click Thread Group -> Add -> Sampler -> Cassandra Batch Put. A sample screenhot is shown below
This is very similar to Put but you can specify multiple columns for the row. The format for each column is <column name>:<value>

View Results Tree now shows us each transaction was a Batch Put and the Sampler result has all the column names and values

Again cassandra-cli shows us our data was inserted correctly
[default@unknown] use MemberKeySp;
Authenticated to keyspace: MemberKeySp
[default@MemberKeySp] list Customer;
Using default limit of 100
-------------------
RowKey: 3
=> (column=580, value=746573745f646174615f646464, timestamp=1330036037925001)
=> (column=constant, value=746573745f646174615f646464, timestamp=1330036037925000)
-------------------
RowKey: 6
=> (column=628, value=746573745f646174615f676767, timestamp=1330036038190001)
=> (column=constant, value=746573745f646174615f676767, timestamp=1330036038190000)
Often Cassandra keyspaces use composite columns to store data. Consider the following example where we have a keyspace called MemberKeySp and a Column Family Customer. The column is a composite column consisting of an Integer:UTF8
drop keyspace MemberKeySp;
create keyspace MemberKeySp
with placement_strategy = 'NetworkTopologyStrategy'
and strategy_options = { us-east : 3 }
and durable_writes = true;
use MemberKeySp;
create column family Customer
with column_type = 'Standard'
and comparator = 'CompositeType(org.apache.cassandra.db.marshal.IntegerType,org.apache.cassandra.db.marshal.UTF8Type)'
and default_validation_class = 'BytesType'
and key_validation_class = 'UTF8Type'
and memtable_operations = 1.0
and memtable_throughput = 64
and rows_cached = 1000.0
and row_cache_save_period = 0
and keys_cached = 300000.0
and key_cache_save_period = 14400
and read_repair_chance = 0.0
and gc_grace = 864000
and min_compaction_threshold = 4
and max_compaction_threshold = 32
and replicate_on_write = false
and row_cache_provider = 'ConcurrentLinkedHashCacheProvider'
and comment = 'Customer-specific, ABTest allocations';
We create a csv file which contains 3 fields that looks like this.
0,1:comp111,ef3e0b
0,2:comp222,1de7c16
0,3:comp333,2cdba21
0,4:comp444,3bcf82c
0,5:comp555,4ac3637
1,0:comp666,59b7442
1,1:comp777,68ab24d
1,2:comp888,779f058
1,3:comp999,8692e63
1,4:comp101010,9586c6e
1,5:comp111111,a47aa79
In JMeter right click on the Thread Group -> Add -> Sampler -> Cassandra Composite Put. The screenshot below shows our example. Note we dont need to specify the format of the composite column as this is derived from the schema

The View Reults Tree shows the Composite Put success and the Composite Column name
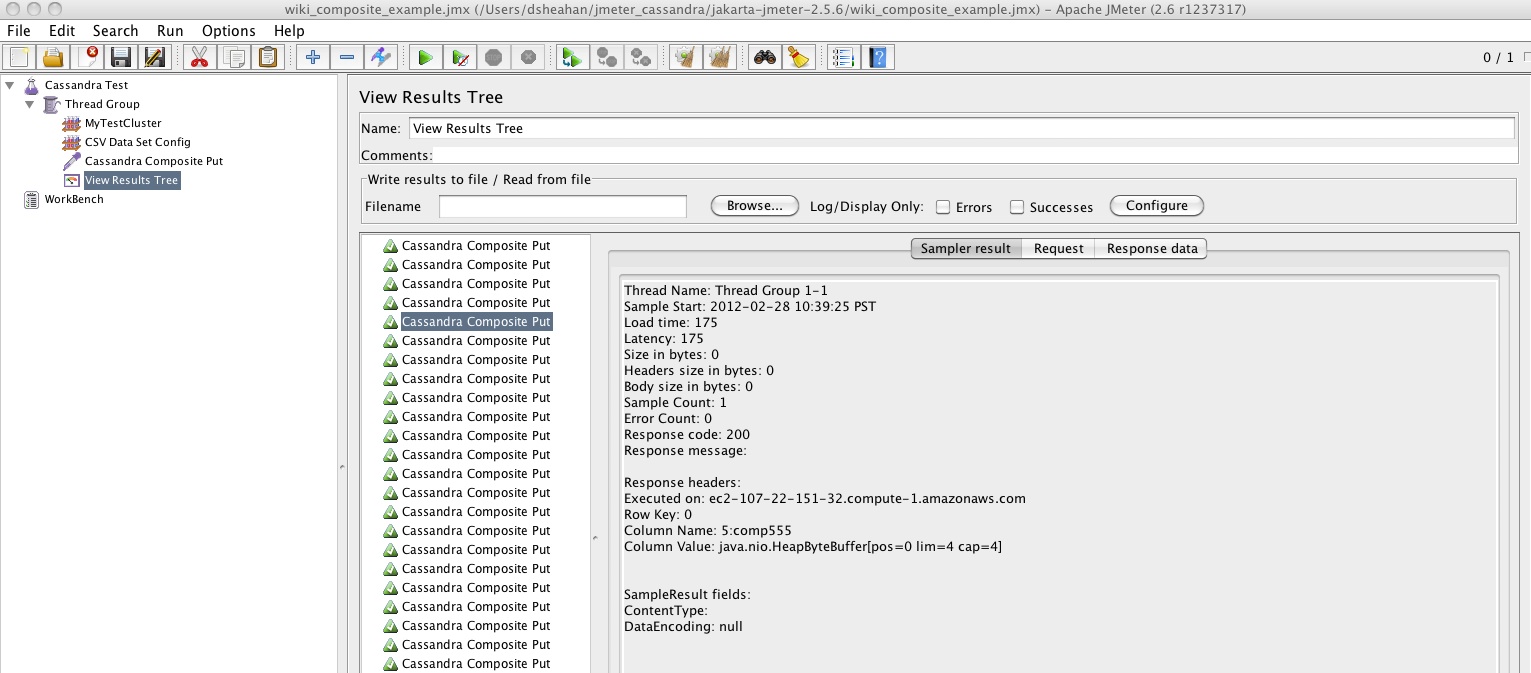
cassandra-cli shows us how these Composite Columns have been loaded
[default@MemberKeySp] list Customer;
Using default limit of 100
-------------------
RowKey: 3
=> (column=0:comp181818, value=10d25cc6, timestamp=1330057016537000)
=> (column=1:comp191919, value=11c19ad1, timestamp=1330057016648000)
=> (column=2:comp202020, value=12b0d8dc, timestamp=1330057016759000)
=> (column=3:comp212121, value=13a016e7, timestamp=1330057016872000)
=> (column=4:comp222222, value=148f54f2, timestamp=1330057016981000)
=> (column=5:comp232323, value=157e92fd, timestamp=1330057017093000)
-------------------
RowKey: 0
=> (column=1:comp111, value=ef3e0b, timestamp=1330057014678000)
=> (column=2:comp222, value=01de7c16, timestamp=1330057014789000)
=> (column=3:comp333, value=02cdba21, timestamp=1330057014898000)
=> (column=4:comp444, value=03bcf82c, timestamp=1330057015004000)
=> (column=5:comp555, value=04ac3637, timestamp=1330057015118000)
-------------------
RowKey: 2
=> (column=0:comp121212, value=0b36e884, timestamp=1330057015883000)
=> (column=1:comp131313, value=0c26268f, timestamp=1330057015996000)
=> (column=2:comp141414, value=0d15649a, timestamp=1330057016101000)
=> (column=3:comp151515, value=0e04a2a5, timestamp=1330057016210000)
=> (column=4:comp161616, value=0ef3e0b0, timestamp=1330057016318000)
=> (column=5:comp171717, value=0fe31ebb, timestamp=1330057016429000)
-------------------
The simplest form of Get that the JMeter plugin performs just fetches a single column from a row given a rowid and column name. Looking at the screen shot we need to specify

-
ROW KEY the rowid to use for teh get. This can be a random number, JMeter variable or constant
-
COLUMN NAME . The column within the row to return again, this can be a random number, JMeter variable or constant
-
Key, Column and Value Serializers As with Put this can be one of AsciiSerializer, BooleanSerializer, DateSerializer, BytesSerializer, CharSerializer, StringSerializer, FloatSerializer, UUIDSerializer, IntegerSerializer, DoubleSerializer, ShortSerializer, LongSerializer, BigIntegerSerializer.
As an example lets use the simple schema we created at the start and change the data in the csv fila (rowid, column_name, data) to give each row multiple columns
1,0,test_data_bbb
1,1,test_data_bbb
1,2,test_data_bbb
1,3,test_data_bbb
1,4,test_data_bbb
2,0,test_data_ccc
2,1,test_data_ccc
2,2,test_data_ccc
2,3,test_data_ccc
2,4,test_data_ccc
3,0,test_data_ddd
3,1,test_data_ddd
3,2,test_data_ddd
3,3,test_data_ddd
3,4,test_data_ddd
4,0,test_data_eee
4,1,test_data_eee
4,2,test_data_eee
We then use a simple JMeter Put to load the data into the Customer Column Family. cassandra-cli shows that each row now has 5 columns
[default@MemberKeySp] list Customer;
Using default limit of 100
-------------------
RowKey: 3
=> (column=0, value=746573745f646174615f616161, timestamp=1330065401292000)
=> (column=1, value=746573745f646174615f626262, timestamp=1330065401402000)
=> (column=2, value=746573745f646174615f636363, timestamp=1330065401508000)
=> (column=3, value=746573745f646174615f646464, timestamp=1330065401620000)
=> (column=4, value=746573745f646174615f656565, timestamp=1330065401726000)
-------------------
RowKey: 6
=> (column=0, value=746573745f646174615f616161, timestamp=1330065402935000)
=> (column=1, value=746573745f646174615f626262, timestamp=1330065403040000)
=> (column=2, value=746573745f646174615f636363, timestamp=1330065403150000)
=> (column=3, value=746573745f646174615f646464, timestamp=1330065403259000)
=> (column=4, value=746573745f646174615f656565, timestamp=1330065403369000)
...
In our screenshot example we use the simple Get to extract just column 2 from the first 25 rows. The reults of the Get will be in the Response window of the View Response Tree Listener in this case the single column value

If you want to retrieve more than one column from a row use the Get Range Slice Sampler. There are a number of ways to specify the range.
-
By leaving START COLUMN NAME and END COLUMN NAME blank and just specifying COUNT, you get the first COUNT columns. To get the entire range just set COUNT to be a large number
-
If you can set the START to 2 and leave END blank you wil get columns 2, 3, 4
-
If you set START to 1 and END to 3 you will get columns 1,2,3. This example is shown in the screenshot.
One gotcha is the Reverse checkbox. If this is set data will be returned in reverse. When checked, however, the START column specified must be greater than END or you will get an error

The last Get option is Composite Column. This allows you to extract a single column from a row with a Composite Column name. The format of the Column name is :
So again looking at out composite column csv file which has fields we can use the first two entries to extract the columns
0,1:comp111,ef3e0b
0,2:comp222,1de7c16
0,3:comp333,2cdba21
0,4:comp444,3bcf82c
0,5:comp555,4ac3637
1,0:comp666,59b7442
1,1:comp777,68ab24d
1,2:comp888,779f058
1,3:comp999,8692e63
The screenshot for the composite column get is shown below
