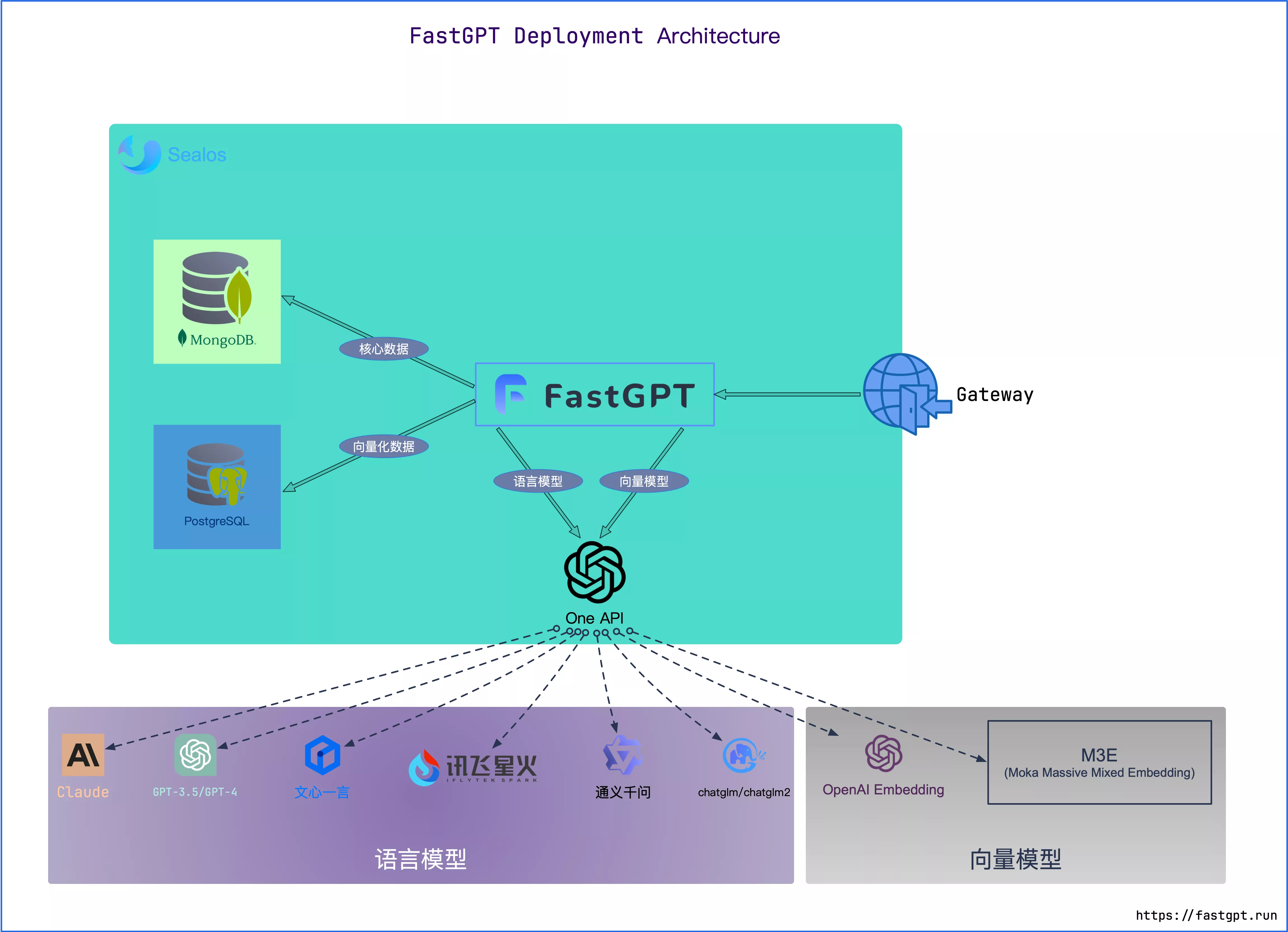
+和上一个问题一样,curl 测试。知识库索引没有进度/索引很慢 link 先看日志报错信息。有以下几种情况:
可以对话,但是索引没有进度:没有配置向量模型(vectorModels) 不能对话,也不能索引:API调用失败。可能是没连上OneAPI或OpenAI 有进度,但是非常慢:api key不行,OpenAI的免费号,一分钟只有3次还是60次。一天上限200次。 Connection error link 网络异常。国内服务器无法请求OpenAI,自行检查与AI模型的连接是否正常。
或者是FastGPT请求不到 OneAPI(没放同一个网络)
修改了 vectorModels 但是没有生效 link 重启容器,确保模型配置已经加载(可以在日志或者新建知识库时候看到新模型) 记得刷新一次浏览器。 如果是已经创建的知识库,需要删除重建。向量模型是创建时候绑定的,不会动态更新。 三、常见的 OneAPI 错误 link 带有 requestId 的都是 OneAPI 的报错。
insufficient_user_quota user quota is not enough link OneAPI 账号的余额不足,默认 root 用户只有 200 刀,可以手动修改。
路径:打开OneAPI -> 用户 -> root用户右边的编辑 -> 剩余余额调大
xxx渠道找不到 link FastGPT 模型配置文件中的 model 必须与 OneAPI 渠道中的模型对应上,否则就会提示这个错误。可检查下面内容:
OneAPI 中没有配置该模型渠道,或者被禁用了。 FastGPT 配置文件有 OneAPI 没有配置的模型。如果 OneAPI 没有配置对应模型的,配置文件中也不要写。 使用旧的向量模型创建了知识库,后又更新了向量模型。这时候需要删除以前的知识库,重建。 如果OneAPI中,没有配置对应的模型,config.json中也不要配置,否则容易报错。
点击模型测试失败 link OneAPI 只会测试渠道的第一个模型,并且只会测试对话模型,向量模型无法自动测试,需要手动发起请求进行测试。查看测试模型命令示例
get request url failed: Post “https://xxx dial tcp: xxxx link OneAPI 与模型网络不通,需要检查网络配置。
Incorrect API key provided: sk-xxxx.You can find your api Key at xxx link OneAPI 的 API Key 配置错误,需要修改OPENAI_API_KEY环境变量,并重启容器(先 docker-compose down 然后再 docker-compose up -d 运行一次)。
可以exec进入容器,env查看环境变量是否生效。
bad_response_status_code bad response status code 503 link 模型服务不可用 模型接口参数异常(温度、max token等可能不适配) …. 四、常见模型问题 link 如何检查模型问题 link 私有部署模型,先确认部署的模型是否正常。 通过 CURL 请求,直接测试上游模型是否正常运行(云端模型或私有模型均进行测试) 通过 CURL 请求,请求 OneAPI 去测试模型是否正常。 在 FastGPT 中使用该模型进行测试。 下面是几个测试 CURL 示例:
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
@@ -56,7 +56,7 @@
}
]
}'
-
curl https://api.openai.com/v1/embeddings \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
@@ -65,7 +65,7 @@
"model": "text-embedding-ada-002",
"encoding_format": "float"
}'
-
curl --location --request POST 'https://xxxx.com/api/v1/rerank' \
--header 'Authorization: Bearer {{ACCESS_TOKEN}}' \
--header 'Content-Type: application/json' \
@@ -76,7 +76,7 @@
"你是谁?\n我是电影《铃芽之旅》助手"
]
}'
-
curl https://api.openai.com/v1/audio/speech \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
@@ -86,7 +86,7 @@
"voice": "alloy"
}' \
--output speech.mp3
-
curl https://api.openai.com/v1/audio/transcriptions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: multipart/form-data" \
diff --git a/docs/development/openapi/chat/index.html b/docs/development/openapi/chat/index.html
index 883c1c5cc11c..f622558c2706 100644
--- a/docs/development/openapi/chat/index.html
+++ b/docs/development/openapi/chat/index.html
@@ -34,9 +34,9 @@
-Table of Contents
chat
对话接口 FastGPT OpenAPI 对话接口
请求简易应用和工作流 link 对话接口兼容GPT的接口!如果你的项目使用的是标准的GPT官方接口,可以直接通过修改BaseUrl和 Authorization来访问 FastGpt 应用,不过需要注意下面几个规则:
chat
对话接口 FastGPT OpenAPI 对话接口
请求简易应用和工作流 link 对话接口兼容GPT的接口!如果你的项目使用的是标准的GPT官方接口,可以直接通过修改BaseUrl和 Authorization来访问 FastGpt 应用,不过需要注意下面几个规则:
curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxxxxx' \
--header 'Content-Type: application/json' \
@@ -56,7 +56,7 @@
}
]
}'
- 仅messages有部分区别,其他参数一致。 目前不支持上次文件,需上传到自己的对象存储中,获取对应的文件链接。 仅messages有部分区别,其他参数一致。 目前不支持上次文件,需上传到自己的对象存储中,获取对应的文件链接。
curl --location --request POST 'http://localhost:3000/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxxxxx' \
--header 'Content-Type: application/json' \
@@ -86,11 +86,11 @@
}
]
}'
- info
headers.Authorization: Bearer {{apikey}} chatId: string | undefined 。为 undefined 时(不传入),不使用 FastGpt 提供的上下文功能,完全通过传入的 messages 构建上下文。 不会将你的记录存储到数据库中,你也无法在记录汇总中查阅到。 为非空字符串时,意味着使用 chatId 进行对话,自动从 FastGpt 数据库取历史记录,并使用 messages 数组最后一个内容作为用户问题。请自行确保 chatId 唯一,长度小于250,通常可以是自己系统的对话框ID。 messages: 结构与 GPT接口 chat模式一致。 responseChatItemId: string | undefined 。如果传入,则会将该值作为本次对话的响应消息的 ID,FastGPT 会自动将该 ID 存入数据库。请确保,在当前chatId下,responseChatItemId是唯一的。 detail: 是否返回中间值(模块状态,响应的完整结果等),stream模式下会通过event进行区分,非stream模式结果保存在responseData中。 variables: 模块变量,一个对象,会替换模块中,输入框内容里的{{key}} info
headers.Authorization: Bearer {{apikey}} chatId: string | undefined 。为 undefined 时(不传入),不使用 FastGpt 提供的上下文功能,完全通过传入的 messages 构建上下文。 不会将你的记录存储到数据库中,你也无法在记录汇总中查阅到。 为非空字符串时,意味着使用 chatId 进行对话,自动从 FastGpt 数据库取历史记录,并使用 messages 数组最后一个内容作为用户问题。请自行确保 chatId 唯一,长度小于250,通常可以是自己系统的对话框ID。 messages: 结构与 GPT接口 chat模式一致。 responseChatItemId: string | undefined 。如果传入,则会将该值作为本次对话的响应消息的 ID,FastGPT 会自动将该 ID 存入数据库。请确保,在当前chatId下,responseChatItemId是唯一的。 detail: 是否返回中间值(模块状态,响应的完整结果等),stream模式下会通过event进行区分,非stream模式结果保存在responseData中。 variables: 模块变量,一个对象,会替换模块中,输入框内容里的{{key}}
{
"id": "adsfasf",
"model": "",
@@ -110,7 +110,7 @@
}
]
}
-
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":""},"index":0,"finish_reason":null}]}
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":"电"},"index":0,"finish_reason":null}]}
@@ -118,7 +118,7 @@
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":"影"},"index":0,"finish_reason":null}]}
data: {"id":"","object":"","created":0,"choices":[{"delta":{"content":"《"},"index":0,"finish_reason":null}]}
-
{
"responseData": [ // 不同模块的响应值, 不同版本具体值可能有差异,可先 log 自行查看最新值。
{
@@ -202,7 +202,7 @@
}
]
}
-
event: flowNodeStatus
data: {"status":"running","name":"知识库搜索"}
@@ -232,8 +232,8 @@
event: flowResponses
data: [{"moduleName":"知识库搜索","moduleType":"datasetSearchNode","runningTime":1.78},{"question":"导演是谁","quoteList":[{"id":"654f2e49b64caef1d9431e8b","q":"电影《铃芽之旅》的导演是谁?","a":"电影《铃芽之旅》的导演是新海诚!","indexes":[{"type":"qa","dataId":"3515487","text":"电影《铃芽之旅》的导演是谁?","_id":"654f2e49b64caef1d9431e8c","defaultIndex":true}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8935586214065552},{"id":"6552e14c50f4a2a8e632af11","q":"导演是谁?","a":"电影《铃芽之旅》的导演是新海诚。","indexes":[{"defaultIndex":true,"type":"qa","dataId":"3644565","text":"导演是谁?\n电影《铃芽之旅》的导演是新海诚。","_id":"6552e14dde5cc7ba3954e417"}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8890955448150635},{"id":"654f34a0b64caef1d946337e","q":"本作的主人公是谁?","a":"本作的主人公是名叫铃芽的少女。","indexes":[{"type":"qa","dataId":"3515541","text":"本作的主人公是谁?","_id":"654f34a0b64caef1d946337f","defaultIndex":true}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8738770484924316},{"id":"654f3002b64caef1d944207a","q":"电影《铃芽之旅》男主角是谁?","a":"电影《铃芽之旅》男主角是宗像草太,由松村北斗配音。","indexes":[{"type":"qa","dataId":"3515538","text":"电影《铃芽之旅》男主角是谁?","_id":"654f3002b64caef1d944207b","defaultIndex":true}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8607980012893677},{"id":"654f2fc8b64caef1d943fd46","q":"电影《铃芽之旅》的编剧是谁?","a":"新海诚是本片的编剧。","indexes":[{"defaultIndex":true,"type":"qa","dataId":"3515550","text":"电影《铃芽之旅》的编剧是谁?22","_id":"654f2fc8b64caef1d943fd47"}],"datasetId":"646627f4f7b896cfd8910e38","collectionId":"653279b16cd42ab509e766e8","sourceName":"data (81).csv","sourceId":"64fd3b6423aa1307b65896f6","score":0.8468944430351257}],"moduleName":"AI 对话","moduleType":"chatNode","runningTime":1.86}]
- event取值:
answer: 返回给客户端的文本(最终会算作回答) fastAnswer: 指定回复返回给客户端的文本(最终会算作回答) toolCall: 执行工具 toolParams: 工具参数 toolResponse: 工具返回 flowNodeStatus: 运行到的节点状态 flowResponses: 节点完整响应 updateVariables: 更新变量 error: 报错 如果工作流中包含交互节点,依然是调用该 API 接口,需要设置detail=true,并可以从event=interactive的数据中获取交互节点的配置信息。如果是stream=false,则可以从 choice 中获取type=interactive的元素,获取交互节点的选择信息。
当你调用一个带交互节点的工作流时,如果工作流遇到了交互节点,那么会直接返回,你可以得到下面的信息:
event取值:
answer: 返回给客户端的文本(最终会算作回答) fastAnswer: 指定回复返回给客户端的文本(最终会算作回答) toolCall: 执行工具 toolParams: 工具参数 toolResponse: 工具返回 flowNodeStatus: 运行到的节点状态 flowResponses: 节点完整响应 updateVariables: 更新变量 error: 报错 如果工作流中包含交互节点,依然是调用该 API 接口,需要设置detail=true,并可以从event=interactive的数据中获取交互节点的配置信息。如果是stream=false,则可以从 choice 中获取type=interactive的元素,获取交互节点的选择信息。
当你调用一个带交互节点的工作流时,如果工作流遇到了交互节点,那么会直接返回,你可以得到下面的信息:
{
"interactive": {
"type": "userSelect",
@@ -252,7 +252,7 @@
}
}
}
-
{
"interactive": {
"type": "userInput",
@@ -295,8 +295,8 @@
}
}
}
- 交互节点继续运行 link 紧接着上一节,当你接收到交互节点信息后,可以根据这些数据进行 UI 渲染,引导用户输入或选择相关信息。然后需要再次发起对话,来继续工作流。调用的接口与仍是该接口,你需要按以下格式来发起请求:
对于用户选择,你只需要直接传递一个选择的结果给 messages 即可。
交互节点继续运行 link 紧接着上一节,当你接收到交互节点信息后,可以根据这些数据进行 UI 渲染,引导用户输入或选择相关信息。然后需要再次发起对话,来继续工作流。调用的接口与仍是该接口,你需要按以下格式来发起请求:
对于用户选择,你只需要直接传递一个选择的结果给 messages 即可。
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxx' \
--header 'Content-Type: application/json' \
@@ -311,7 +311,7 @@
}
]
}'
- 表单输入稍微麻烦一点,需要将输入的内容,以对象形式并序列化成字符串,作为messages的值。对象的 key 对应表单的 key,value 为用户输入的值。务必确保chatId是一致的。
表单输入稍微麻烦一点,需要将输入的内容,以对象形式并序列化成字符串,作为messages的值。对象的 key 对应表单的 key,value 为用户输入的值。务必确保chatId是一致的。
curl --location --request POST 'https://api.fastgpt.in/api/v1/chat/completions' \
--header 'Authorization: Bearer fastgpt-xxxx' \
--header 'Content-Type: application/json' \
@@ -337,9 +337,9 @@
"query":"你好" # 我的插件输入有一个参数,变量名叫 query
}
}'
- 插件的输出可以通过查找responseData中, moduleType=pluginOutput的元素,其pluginOutput是插件的输出。 流输出,仍可以通过choices进行获取。 插件的输出可以通过查找responseData中, moduleType=pluginOutput的元素,其pluginOutput是插件的输出。 流输出,仍可以通过choices进行获取。
{
"responseData": [
{
@@ -396,7 +396,7 @@
}
]
}
- 插件的输出可以通过获取event=flowResponses中的字符串,并将其反序列化后得到一个数组。同样的,查找 moduleType=pluginOutput的元素,其pluginOutput是插件的输出。 流输出,仍和对话接口一样获取。 插件的输出可以通过获取event=flowResponses中的字符串,并将其反序列化后得到一个数组。同样的,查找 moduleType=pluginOutput的元素,其pluginOutput是插件的输出。 流输出,仍和对话接口一样获取。
event: flowNodeStatus
data: {"status":"running","name":"AI 对话"}
@@ -453,9 +453,9 @@
event: flowResponses
data: [{"nodeId":"fdDgXQ6SYn8v","moduleName":"AI 对话","moduleType":"chatNode","totalPoints":0.033,"model":"FastAI-3.5","tokens":33,"query":"你好","maxToken":2000,"historyPreview":[{"obj":"Human","value":"你好"},{"obj":"AI","value":"你好!有什么可以帮助你的吗?"}],"contextTotalLen":2,"runningTime":1.42},{"nodeId":"pluginOutput","moduleName":"插件输出","moduleType":"pluginOutput","totalPoints":0,"pluginOutput":{"result":"你好!有什么可以帮助你的吗?"},"runningTime":0}]
- event取值:
answer: 返回给客户端的文本(最终会算作回答) fastAnswer: 指定回复返回给客户端的文本(最终会算作回答) toolCall: 执行工具 toolParams: 工具参数 toolResponse: 工具返回 flowNodeStatus: 运行到的节点状态 flowResponses: 节点完整响应 updateVariables: 更新变量 error: 报错 以下接口可使用任意API Key调用。
4.8.12 以上版本才能使用
重要字段
chatId - 指一个应用下,某一个对话窗口的 ID dataId - 指一个对话窗口下,某一个对话记录的 ID 获取某个应用历史记录 link event取值:
answer: 返回给客户端的文本(最终会算作回答) fastAnswer: 指定回复返回给客户端的文本(最终会算作回答) toolCall: 执行工具 toolParams: 工具参数 toolResponse: 工具返回 flowNodeStatus: 运行到的节点状态 flowResponses: 节点完整响应 updateVariables: 更新变量 error: 报错 以下接口可使用任意API Key调用。
4.8.12 以上版本才能使用
重要字段
chatId - 指一个应用下,某一个对话窗口的 ID dataId - 指一个对话窗口下,某一个对话记录的 ID 获取某个应用历史记录 link
curl --location --request POST 'http://localhost:3000/api/core/chat/getHistories' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -465,7 +465,7 @@
"pageSize": 20,
"source: "api"
}'
-
appId - 应用 Id offset - 偏移量,即从第几条数据开始取 pageSize - 记录数量 source - 对话源
appId - 应用 Id offset - 偏移量,即从第几条数据开始取 pageSize - 记录数量 source - 对话源
{
"code": 200,
"statusText": "",
@@ -492,9 +492,9 @@
"total": 2
}
}
- 修改某个对话的标题 link 修改某个对话的标题 link
curl --location --request POST 'http://localhost:3000/api/core/chat/updateHistory' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -503,16 +503,16 @@
"chatId": "chatId",
"customTitle": "自定义标题"
}'
-
appId - 应用 Id chatId - 历史记录 Id customTitle - 自定义对话名
appId - 应用 Id chatId - 历史记录 Id customTitle - 自定义对话名
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 置顶 / 取消置顶 link 置顶 / 取消置顶 link
curl --location --request POST 'http://localhost:3000/api/core/chat/updateHistory' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -521,43 +521,43 @@
"chatId": "chatId",
"top": true
}'
-
appId - 应用Id chatId - 历史记录 Id top - 是否置顶,ture 置顶,false 取消置顶
appId - 应用Id chatId - 历史记录 Id top - 是否置顶,ture 置顶,false 取消置顶
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 删除某个历史记录 link 删除某个历史记录 link
curl --location --request DELETE 'http://localhost:3000/api/core/chat/delHistory?chatId={{chatId}}&appId={{appId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
appId - 应用 Id chatId - 历史记录 Id
appId - 应用 Id chatId - 历史记录 Id
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 清空所有历史记录 link 仅会情况通过 API Key 创建的对话历史记录,不会清空在线使用、分享链接等其他来源的对话历史记录。
清空所有历史记录 link 仅会情况通过 API Key 创建的对话历史记录,不会清空在线使用、分享链接等其他来源的对话历史记录。
curl --location --request DELETE 'http://localhost:3000/api/core/chat/clearHistories?appId={{appId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 指的是某个 chatId 下的对话记录操作。
获取单个对话初始化信息 link 指的是某个 chatId 下的对话记录操作。
获取单个对话初始化信息 link
curl --location --request GET 'http://localhost:3000/api/core/chat/init?appId={{appId}}&chatId={{chatId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
appId - 应用 Id chatId - 历史记录 Id
appId - 应用 Id chatId - 历史记录 Id
{
"code": 200,
"statusText": "",
@@ -611,9 +611,9 @@
}
}
}
- 获取对话记录列表 link 获取对话记录列表 link
curl --location --request POST 'http://localhost:3000/api/core/chat/getPaginationRecords' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -624,7 +624,7 @@
"pageSize": 10,
"loadCustomFeedbacks": true
}'
-
appId - 应用 Id chatId - 历史记录 Id offset - 偏移量 pageSize - 记录数量 loadCustomFeedbacks - 是否读取自定义反馈(可选)
appId - 应用 Id chatId - 历史记录 Id offset - 偏移量 pageSize - 记录数量 loadCustomFeedbacks - 是否读取自定义反馈(可选)
{
"code": 200,
"statusText": "",
@@ -673,12 +673,12 @@
"total": 2
}
}
- 获取单个对话记录运行详情 link 获取单个对话记录运行详情 link
curl --location --request GET 'http://localhost:3000/api/core/chat/getResData?appId={{appId}}&chatId={{chatId}}&dataId={{dataId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
appId - 应用 Id chatId - 对话 Id dataId - 对话记录 Id
appId - 应用 Id chatId - 对话 Id dataId - 对话记录 Id
{
"code": 200,
"statusText": "",
@@ -724,21 +724,21 @@
}
]
}
-
curl --location --request DELETE 'http://localhost:3000/api/core/chat/item/delete?contentId={{contentId}}&chatId={{chatId}}&appId={{appId}}' \
--header 'Authorization: Bearer {{apikey}}'
-
appId - 应用 Id chatId - 历史记录 Id contentId - 对话记录 Id
appId - 应用 Id chatId - 历史记录 Id contentId - 对话记录 Id
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 点赞 / 取消点赞 link 点赞 / 取消点赞 link
curl --location --request POST 'http://localhost:3000/api/core/chat/feedback/updateUserFeedback' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -748,16 +748,16 @@
"dataId": "dataId",
"userGoodFeedback": "yes"
}'
-
appId - 应用 Id chatId - 历史记录 Id dataId - 对话记录 Id userGoodFeedback - 用户点赞时的信息(可选),取消点赞时不填此参数即可
appId - 应用 Id chatId - 历史记录 Id dataId - 对话记录 Id userGoodFeedback - 用户点赞时的信息(可选),取消点赞时不填此参数即可
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 点踩 / 取消点踩 link 点踩 / 取消点踩 link
curl --location --request POST 'http://localhost:3000/api/core/chat/feedback/updateUserFeedback' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -767,16 +767,16 @@
"dataId": "dataId",
"userBadFeedback": "yes"
}'
-
appId - 应用 Id chatId - 历史记录 Id dataId - 对话记录 Id userBadFeedback - 用户点踩时的信息(可选),取消点踩时不填此参数即可
appId - 应用 Id chatId - 历史记录 Id dataId - 对话记录 Id userBadFeedback - 用户点踩时的信息(可选),取消点踩时不填此参数即可
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 4.8.16 后新版接口
新版猜你想问,必须包含 appId 和 chatId 的参数才可以进行使用。会自动根据 chatId 去拉取最近 6 轮对话记录作为上下文来引导回答。
4.8.16 后新版接口
新版猜你想问,必须包含 appId 和 chatId 的参数才可以进行使用。会自动根据 chatId 去拉取最近 6 轮对话记录作为上下文来引导回答。
curl --location --request POST 'http://localhost:3000/api/core/ai/agent/v2/createQuestionGuide' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -789,7 +789,7 @@
"customPrompt": "你是一个智能助手,请根据用户的问题生成猜你想问。"
}
}'
-
参数名 类型 必填 说明 appId string ✅ 应用 Id chatId string ✅ 对话 Id questionGuide object 自定义配置,不传的话,则会根据 appId,取最新发布版本的配置
参数名 类型 必填 说明 appId string ✅ 应用 Id chatId string ✅ 对话 Id questionGuide object 自定义配置,不传的话,则会根据 appId,取最新发布版本的配置
type CreateQuestionGuideParams = OutLinkChatAuthProps & {
appId: string;
chatId: string;
@@ -799,7 +799,7 @@
customPrompt?: string;
};
};
-
{
"code": 200,
"statusText": "",
@@ -810,9 +810,9 @@
"你希望AI能做什么?"
]
}
- 4.8.16 前旧版接口:
4.8.16 前旧版接口:
curl --location --request POST 'http://localhost:3000/api/core/ai/agent/createQuestionGuide' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -828,7 +828,7 @@
}
]
}'
-
messages - 对话消息,提供给 AI 的消息记录
messages - 对话消息,提供给 AI 的消息记录
{
"code": 200,
"statusText": "",
diff --git a/docs/development/openapi/dataset/index.html b/docs/development/openapi/dataset/index.html
index dee97e01233d..9441a80ab2d0 100644
--- a/docs/development/openapi/dataset/index.html
+++ b/docs/development/openapi/dataset/index.html
@@ -34,8 +34,8 @@
-Table of Contents
dataset
知识库接口 FastGPT OpenAPI 知识库接口
如何获取知识库ID(datasetId) 如何获取文件集合ID(collection_id)
新例子
dataset
知识库接口 FastGPT OpenAPI 知识库接口
如何获取知识库ID(datasetId) 如何获取文件集合ID(collection_id)
新例子
curl --location --request POST 'http://localhost:3000/api/support/wallet/usage/createTrainingUsage' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
@@ -43,16 +43,16 @@
"datasetId": "知识库 ID",
"name": "可选,自定义订单名称,例如:文档训练-fastgpt.docx"
}'
- data 为 billId,可用于添加知识库数据时进行账单聚合。
data 为 billId,可用于添加知识库数据时进行账单聚合。
{
"code": 200,
"statusText": "",
"message": "",
"data": "65112ab717c32018f4156361"
}
-
curl --location --request POST 'http://localhost:3000/api/core/dataset/create' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -65,23 +65,23 @@
"vectorModel": "text-embedding-ada-002",
"agentModel": "gpt-3.5-turbo-16k"
}'
-
parentId - 父级ID,用于构建目录结构。通常可以为 null 或者直接不传。 type - dataset或者folder,代表普通知识库和文件夹。不传则代表创建普通知识库。 name - 知识库名(必填) intro - 介绍(可选) avatar - 头像地址(可选) vectorModel - 向量模型(建议传空,用系统默认的) agentModel - 文本处理模型(建议传空,用系统默认的)
parentId - 父级ID,用于构建目录结构。通常可以为 null 或者直接不传。 type - dataset或者folder,代表普通知识库和文件夹。不传则代表创建普通知识库。 name - 知识库名(必填) intro - 介绍(可选) avatar - 头像地址(可选) vectorModel - 向量模型(建议传空,用系统默认的) agentModel - 文本处理模型(建议传空,用系统默认的)
{
"code": 200,
"statusText": "",
"message": "",
"data": "65abc9bd9d1448617cba5e6c"
}
-
curl --location --request POST 'http://localhost:3000/api/core/dataset/list?parentId=' \
--header 'Authorization: Bearer xxxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"parentId":""
}'
-
parentId - 父级ID,传空字符串或者null,代表获取根目录下的知识库
parentId - 父级ID,传空字符串或者null,代表获取根目录下的知识库
{
"code": 200,
"statusText": "",
@@ -108,12 +108,12 @@
}
]
}
-
curl --location --request GET 'http://localhost:3000/api/core/dataset/detail?id=6593e137231a2be9c5603ba7' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
@@ -149,21 +149,21 @@
"isOwner": true
}
}
-
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?id=65abc8729d1448617cba5df6' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- 通用创建参数说明 link 入参
参数 说明 必填 datasetId 知识库ID ✅ parentId: 父级ID,不填则默认为根目录 trainingType 训练模式。chunk: 按文本长度进行分割;qa: QA拆分;auto: 增强训练 ✅ chunkSize 预估块大小 chunkSplitter 自定义最高优先分割符号 qaPrompt qa拆分提示词 tags 集合标签(字符串数组) createTime 文件创建时间(Date / String)
出参
collectionId - 新建的集合ID insertLen:插入的块数量 创建一个空的集合 link 通用创建参数说明 link 入参
参数 说明 必填 datasetId 知识库ID ✅ parentId: 父级ID,不填则默认为根目录 trainingType 训练模式。chunk: 按文本长度进行分割;qa: QA拆分;auto: 增强训练 ✅ chunkSize 预估块大小 chunkSplitter 自定义最高优先分割符号 qaPrompt qa拆分提示词 tags 集合标签(字符串数组) createTime 文件创建时间(Date / String)
出参
collectionId - 新建的集合ID insertLen:插入的块数量 创建一个空的集合 link
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -176,16 +176,16 @@
"test":111
}
}'
-
datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 name: 集合名称(必填) type:folder:文件夹 virtual:虚拟集合(手动集合) metadata: 元数据(暂时没啥用)
datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 name: 集合名称(必填) type:folder:文件夹 virtual:虚拟集合(手动集合) metadata: 元数据(暂时没啥用) data 为集合的 ID。
{
"code": 200,
"statusText": "",
"message": "",
"data": "65abcd009d1448617cba5ee1"
}
- 创建一个纯文本集合 link 传入一段文字,创建一个集合,会根据传入的文字进行分割。
创建一个纯文本集合 link 传入一段文字,创建一个集合,会根据传入的文字进行分割。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/text' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -202,7 +202,7 @@
"metadata":{}
}'
-
text: 原文本 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 name: 集合名称(必填) metadata: 元数据(暂时没啥用) trainingType: 训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选)
text: 原文本 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 name: 集合名称(必填) metadata: 元数据(暂时没啥用) trainingType: 训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选) data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -217,9 +217,9 @@
}
}
}
- 创建一个链接集合 link 传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
创建一个链接集合 link 传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/link' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -237,7 +237,7 @@
"webPageSelector":".docs-content"
}
}'
-
link: 网络链接 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选) trainingType:训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选)
link: 网络链接 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选) trainingType:训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选) data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -252,14 +252,14 @@
}
}
}
- 创建一个文件集合 link 传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
创建一个文件集合 link 传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/localFile' \
--header 'Authorization: Bearer {{authorization}}' \
--form 'file=@"C:\\Users\\user\\Desktop\\fastgpt测试文件\\index.html"' \
--form 'data="{\"datasetId\":\"6593e137231a2be9c5603ba7\",\"parentId\":null,\"trainingType\":\"chunk\",\"chunkSize\":512,\"chunkSplitter\":\"\",\"qaPrompt\":\"\",\"metadata\":{}}"'
- 需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
file: 文件 data: 知识库相关信息(json序列化后传入)datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 trainingType:训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选) 需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
file: 文件 data: 知识库相关信息(json序列化后传入)datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 trainingType:训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选) data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -274,9 +274,9 @@
}
}
}
- 创建一个API集合 link 传入一个文件的 id,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
创建一个API集合 link 传入一个文件的 id,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/apiCollection' \
--header 'Authorization: Bearer fastgpt-xxx' \
--header 'Content-Type: application/json' \
@@ -292,7 +292,7 @@
"chunkSplitter":"",
"qaPrompt":""
}'
- 需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
name: 集合名,建议就用文件名,必填。 apiFileId: 文件的ID,必填。 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 trainingType:训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选) 需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
name: 集合名,建议就用文件名,必填。 apiFileId: 文件的ID,必填。 datasetId: 知识库的ID(必填) parentId: 父级ID,不填则默认为根目录 trainingType:训练模式(必填) chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000) chunkSplitter: 自定义最高优先分割符号(可选) qaPrompt: qa拆分自定义提示词(可选) data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -307,9 +307,9 @@
}
}
}
- 创建一个外部文件库集合(商业版) link 创建一个外部文件库集合(商业版) link
curl --location --request POST 'http://localhost:3000/api/proApi/core/dataset/collection/create/externalFileUrl' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
@@ -328,7 +328,7 @@
"chunkSplitter":"",
"qaPrompt":""
}'
- 参数 说明 必填 externalFileUrl 文件访问链接(可以是临时链接) ✅ externalFileId 外部文件ID filename 自定义文件名,需要带后缀 createTime 文件创建时间(Date ISO 字符串都 ok)
参数 说明 必填 externalFileUrl 文件访问链接(可以是临时链接) ✅ externalFileId 外部文件ID filename 自定义文件名,需要带后缀 createTime 文件创建时间(Date ISO 字符串都 ok)
data 为集合的 ID。
{
"code": 200,
"statusText": "",
@@ -343,9 +343,9 @@
}
}
}
-
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/list' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -356,7 +356,7 @@
"parentId": null,
"searchText":""
}'
-
pageNum: 页码(选填) pageSize: 每页数量,最大30(选填) datasetId: 知识库的ID(必填) parentId: 父级Id(选填) searchText: 模糊搜索文本(选填)
pageNum: 页码(选填) pageSize: 每页数量,最大30(选填) datasetId: 知识库的ID(必填) parentId: 父级Id(选填) searchText: 模糊搜索文本(选填)
{
"code": 200,
"statusText": "",
@@ -418,12 +418,12 @@
"total": 93
}
}
-
curl --location --request GET 'http://localhost:3000/api/core/dataset/collection/detail?id=65abcfab9d1448617cba5f0d' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
@@ -462,9 +462,9 @@
"sourceName": "测试训练"
}
}
- 通过集合 ID 修改集合信息
curl --location --request PUT 'http://localhost:3000/api/core/dataset/collection/update' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -489,29 +489,29 @@
"forbid": false,
"createTime": "2024-01-01T00:00:00.000Z"
}'
-
id: 集合的ID parentId: 修改父级ID(可选) name: 修改集合名称(可选) tags: 修改集合标签(可选) forbid: 修改集合禁用状态(可选) createTime: 修改集合创建时间(可选)
id: 集合的ID parentId: 修改父级ID(可选) name: 修改集合名称(可选) tags: 修改集合标签(可选) forbid: 修改集合禁用状态(可选) createTime: 修改集合创建时间(可选)
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
-
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/collection/delete?id=65aa2a64e6cb9b8ccdc00de8' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
- Data结构
字段 类型 说明 必填 teamId String 团队ID ✅ tmbId String 成员ID ✅ datasetId String 知识库ID ✅ collectionId String 集合ID ✅ q String 主要数据 ✅ a String 辅助数据 ✖ fullTextToken String 分词 ✖ indexes Index[] 向量索引 ✅ updateTime Date 更新时间 ✅ chunkIndex Number 分块下表 ✖
Index结构
每组数据的自定义索引最多5个
字段 类型 说明 必填 defaultIndex Boolean 是否为默认索引 ✅ dataId String 关联的向量ID ✅ text String 文本内容 ✅
为集合批量添加添加数据 link 注意,每次最多推送 200 组数据。
Data结构
字段 类型 说明 必填 teamId String 团队ID ✅ tmbId String 成员ID ✅ datasetId String 知识库ID ✅ collectionId String 集合ID ✅ q String 主要数据 ✅ a String 辅助数据 ✖ fullTextToken String 分词 ✖ indexes Index[] 向量索引 ✅ updateTime Date 更新时间 ✅ chunkIndex Number 分块下表 ✖
Index结构
每组数据的自定义索引最多5个
字段 类型 说明 必填 defaultIndex Boolean 是否为默认索引 ✅ dataId String 关联的向量ID ✅ text String 文本内容 ✅
为集合批量添加添加数据 link 注意,每次最多推送 200 组数据。
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/data/pushData' \
--header 'Authorization: Bearer apikey' \
--header 'Content-Type: application/json' \
@@ -539,7 +539,7 @@
}
]
}'
-
collectionId: 集合ID(必填) trainingType:训练模式(必填) prompt: 自定义 QA 拆分提示词,需严格按照模板,建议不要传入。(选填) data:(具体数据)q: 主要数据(必填) a: 辅助数据(选填) indexes: 自定义索引(选填)。可以不传或者传空数组,默认都会使用q和a组成一个索引。
collectionId: 集合ID(必填) trainingType:训练模式(必填) prompt: 自定义 QA 拆分提示词,需严格按照模板,建议不要传入。(选填) data:(具体数据)q: 主要数据(必填) a: 辅助数据(选填) indexes: 自定义索引(选填)。可以不传或者传空数组,默认都会使用q和a组成一个索引。
{
"code": 200,
"statusText": "",
@@ -550,7 +550,7 @@
"error": [] // 其他错误
}
}
- {{theme}} 里的内容可以换成数据的主题。默认为:它们可能包含多个主题内容
{{theme}} 里的内容可以换成数据的主题。默认为:它们可能包含多个主题内容
我会给你一段文本,{{theme}},学习它们,并整理学习成果,要求为:
1. 提出最多 25 个问题。
2. 给出每个问题的答案。
@@ -564,9 +564,9 @@
……
我的文本:"""{{text}}"""
- 获取集合的数据列表 link 获取集合的数据列表 link 4.8.11+
curl --location --request POST 'http://localhost:3000/api/core/dataset/data/v2/list' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -586,7 +586,7 @@
"collectionId":"65abd4ac9d1448617cba6171",
"searchText":""
}'
-
offset: 偏移量(选填) pageSize: 每页数量,最大30(选填) collectionId: 集合的ID(必填) searchText: 模糊搜索词(选填)
offset: 偏移量(选填) pageSize: 每页数量,最大30(选填) collectionId: 集合的ID(必填) searchText: 模糊搜索词(选填)
{
"code": 200,
"statusText": "",
@@ -613,12 +613,12 @@
"total": 63
}
}
- 获取单条数据详情 link 获取单条数据详情 link
curl --location --request GET 'http://localhost:3000/api/core/dataset/data/detail?id=65abd4b29d1448617cba61db' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
@@ -645,9 +645,9 @@
"canWrite": true
}
}
-
curl --location --request PUT 'http://localhost:3000/api/core/dataset/data/update' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -666,28 +666,28 @@
}
]
}'
-
dataId: 数据的id q: 主要数据(选填) a: 辅助数据(选填) indexes: 自定义索引(选填),类型参考为集合批量添加添加数据。如果创建时候有自定义索引,
dataId: 数据的id q: 主要数据(选填) a: 辅助数据(选填) indexes: 自定义索引(选填),类型参考为集合批量添加添加数据。如果创建时候有自定义索引,
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
-
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/data/delete?id=65abd4b39d1448617cba624d' \
--header 'Authorization: Bearer {{authorization}}' \
-
{
"code": 200,
"statusText": "",
"message": "",
"data": "success"
}
-
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/searchTest' \
--header 'Authorization: Bearer fastgpt-xxxxx' \
--header 'Content-Type: application/json' \
@@ -703,7 +703,7 @@
"datasetSearchExtensionModel": "gpt-4o-mini",
"datasetSearchExtensionBg": ""
}'
-
datasetId - 知识库ID text - 需要测试的文本 limit - 最大 tokens 数量 similarity - 最低相关度(0~1,可选) searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall usingReRank - 使用重排 datasetSearchUsingExtensionQuery - 使用问题优化 datasetSearchExtensionModel - 问题优化模型 datasetSearchExtensionBg - 问题优化背景描述 返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
datasetId - 知识库ID text - 需要测试的文本 limit - 最大 tokens 数量 similarity - 最低相关度(0~1,可选) searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall usingReRank - 使用重排 datasetSearchUsingExtensionQuery - 使用问题优化 datasetSearchExtensionModel - 问题优化模型 datasetSearchExtensionBg - 问题优化背景描述 返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
{
"code": 200,
"statusText": "",
diff --git a/docs/development/openapi/share/index.html b/docs/development/openapi/share/index.html
index d2388af6a33d..5c0d8c0479eb 100644
--- a/docs/development/openapi/share/index.html
+++ b/docs/development/openapi/share/index.html
@@ -43,43 +43,43 @@
"uid": "用户唯一凭证"
}
}
- FastGPT 将会判断success是否为true决定是允许用户继续操作。message与msg是等同的,你可以选择返回其中一个,当success不为true时,将会提示这个错误。
uid是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。
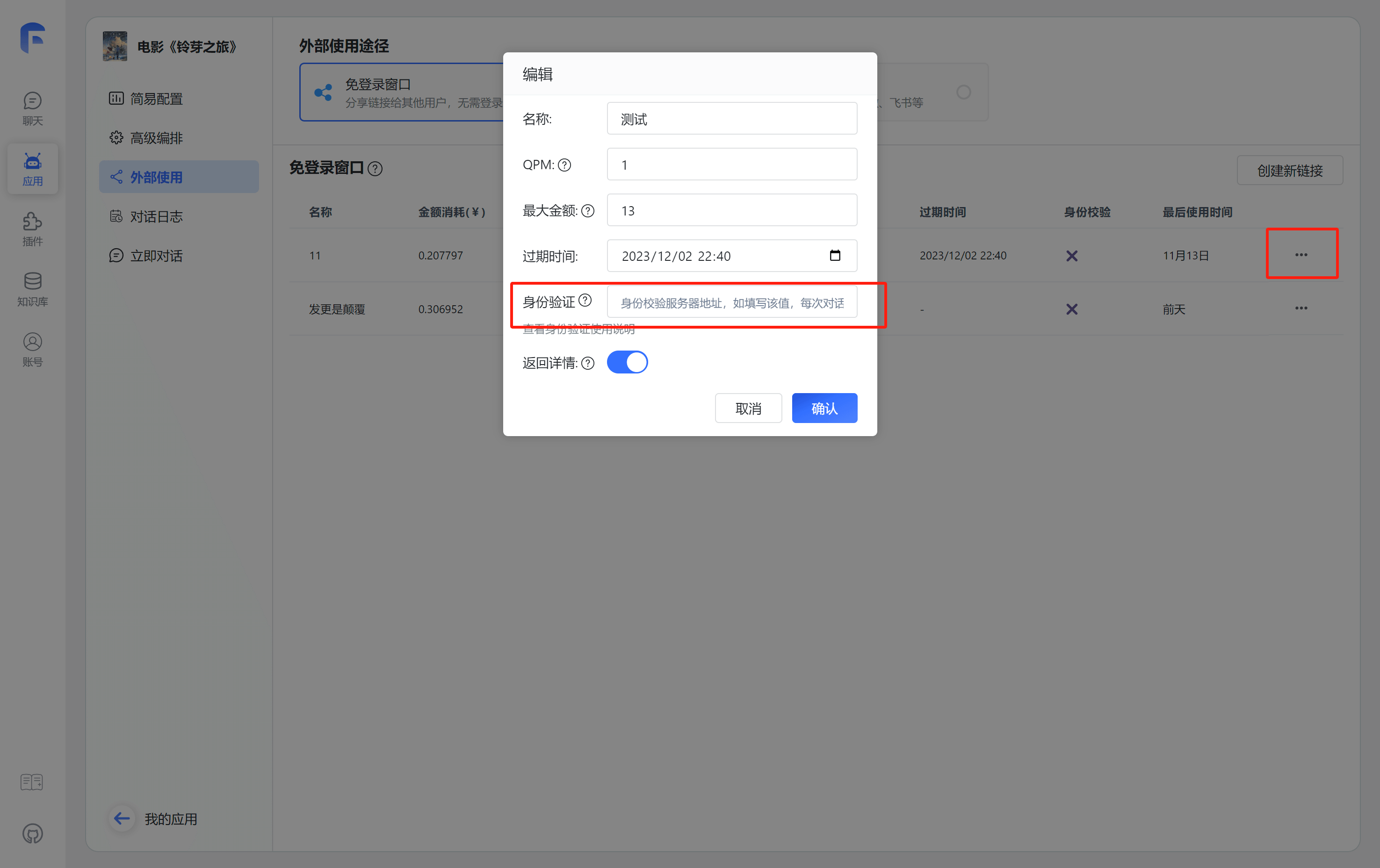
1. 配置身份校验地址 link
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
2. 分享链接中增加额外 query link 在分享链接的地址中,增加一个额外的参数: authToken。例如:
原始的链接:https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192
完整链接: https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345
这个authToken通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的body中携带 token={{authToken}} 的参数。
3. 编写聊天初始化校验接口 link FastGPT 将会判断success是否为true决定是允许用户继续操作。message与msg是等同的,你可以选择返回其中一个,当success不为true时,将会提示这个错误。
uid是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。
1. 配置身份校验地址 link
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
2. 分享链接中增加额外 query link 在分享链接的地址中,增加一个额外的参数: authToken。例如:
原始的链接:https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192
完整链接: https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345
这个authToken通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的body中携带 token={{authToken}} 的参数。
3. 编写聊天初始化校验接口 link
curl --location --request POST '{{host}}/shareAuth/init' \
--header 'Content-Type: application/json' \
--data-raw '{
"token": "{{authToken}}"
}'
-
{
"success": true,
"data": {
"uid": "用户唯一凭证"
}
}
- 系统会拉取该分享链接下,uid 为 username123 的对话记录。
系统会拉取该分享链接下,uid 为 username123 的对话记录。
{
"success": false,
"message": "身份错误",
}
- 4. 编写对话前校验接口 link 4. 编写对话前校验接口 link
curl --location --request POST '{{host}}/shareAuth/start' \
--header 'Content-Type: application/json' \
--data-raw '{
"token": "{{authToken}}",
"question": "用户问题",
}'
-
{
"success": true,
"data": {
"uid": "用户唯一凭证"
}
}
-
{
"success": false,
"message": "身份验证失败",
@@ -202,9 +202,9 @@
isElseResult?: boolean; // 判断器结果
}
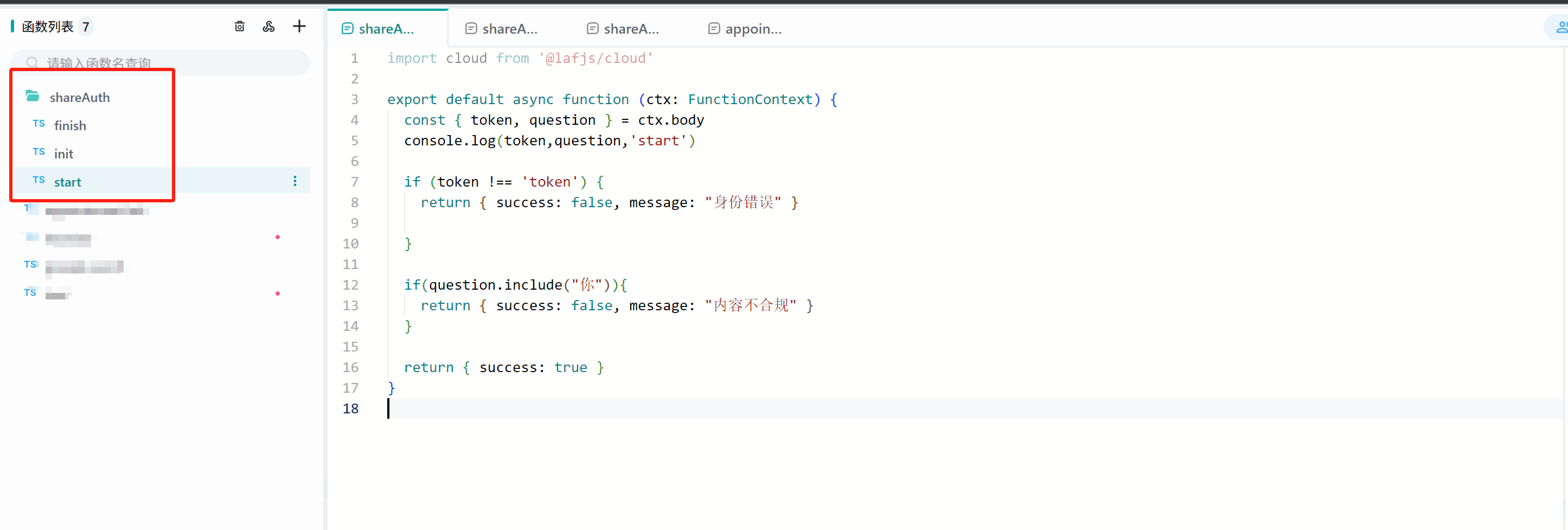
- 我们以Laf作为服务器为例 ,简单展示这 3 个接口的使用方式。
1. 创建3个Laf接口 link
这个接口中,我们设置了token必须等于fastgpt才能通过校验。(实际生产中不建议固定写死)
我们以Laf作为服务器为例 ,简单展示这 3 个接口的使用方式。
1. 创建3个Laf接口 link
这个接口中,我们设置了token必须等于fastgpt才能通过校验。(实际生产中不建议固定写死)
import cloud from '@lafjs/cloud'
export default async function (ctx: FunctionContext) {
@@ -217,7 +217,7 @@
return { success: false,message:"身份错误" }
}
- 这个接口中,我们设置了token必须等于fastgpt才能通过校验。并且如果问题中包含了你字,则会报错,用于模拟敏感校验。
这个接口中,我们设置了token必须等于fastgpt才能通过校验。并且如果问题中包含了你字,则会报错,用于模拟敏感校验。
import cloud from '@lafjs/cloud'
export default async function (ctx: FunctionContext) {
@@ -235,7 +235,7 @@
return { success: true, data: { uid: "user1" } }
}
- 结果上报接口可自行进行逻辑处理。
import cloud from '@lafjs/cloud'
export default async function (ctx: FunctionContext) {
diff --git a/docs/development/upgrading/4818/index.html b/docs/development/upgrading/4818/index.html
index 8f55e979a676..69607dad3cb4 100644
--- a/docs/development/upgrading/4818/index.html
+++ b/docs/development/upgrading/4818/index.html
@@ -34,7 +34,7 @@
-Table of Contents
upgrade
V4.8.18 FastGPT V4.8.18 更新说明
1. 更新镜像: link 更新 fastgpt 镜像 tag: v4.8.18 更新 fastgpt-pro 商业版镜像 tag: v4.8.18 Sandbox 镜像无需更新 2. 运行升级脚本 link 从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 rootkey;{{host}} 替换成FastGPT 域名 。
upgrade
V4.8.18 FastGPT V4.8.18 更新说明
1. 更新镜像: link 更新 fastgpt 镜像 tag: v4.8.18-fix 更新 fastgpt-pro 商业版镜像 tag: v4.8.18-fix Sandbox 镜像无需更新 2. 运行升级脚本 link 从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 rootkey;{{host}} 替换成FastGPT 域名 。
curl --location --request POST 'https://{{host}}/api/admin/initv4818' \
--header 'rootkey: {{rootkey}}' \
--header 'Content-Type: application/json'
diff --git a/docs/development/upgrading/index.xml b/docs/development/upgrading/index.xml
index 37874052e5d9..c73ed9c7d758 100644
--- a/docs/development/upgrading/index.xml
+++ b/docs/development/upgrading/index.xml
@@ -9,7 +9,7 @@ docker-compose pull docker-compose up -d 执行升级初始化脚本 link镜像
QA link为什么需要执行升级脚本 link数据表出现大幅度变更,无法通过设置默认值,或复杂度较高时,会通过升级脚本来更新部分数据表字段。 严格按初始化步骤进行操作,不会造成旧数据丢失。但在初始化过程中,如果数据量大,需要初始化的时间较长,这段时间可能会造成服务无法正常使用。
{{host}} 是什么 link{{}} 代表变量, {{host}}代表一个名为 host 的变量。指的是你服务器的域名或 IP。
Sealos 中,你可以在下图中找到你的域名:
-如何获取 rootkey link从docker-compose.yml中的environment中获取,对应的是ROOT_KEY的值。V4.8.18 Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/4818/ 更新指南 link1. 更新镜像: link 更新 fastgpt 镜像 tag: v4.8.18 更新 fastgpt-pro 商业版镜像 tag: v4.8.18 Sandbox 镜像无需更新 2. 运行升级脚本 link从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 rootkey;{{host}} 替换成FastGPT 域名。
+如何获取 rootkey link从docker-compose.yml中的environment中获取,对应的是ROOT_KEY的值。 V4.8.18 Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/4818/ 更新指南 link1. 更新镜像: link 更新 fastgpt 镜像 tag: v4.8.18-fix 更新 fastgpt-pro 商业版镜像 tag: v4.8.18-fix Sandbox 镜像无需更新 2. 运行升级脚本 link从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 rootkey;{{host}} 替换成FastGPT 域名。
curl --location --request POST 'https://{{host}}/api/admin/initv4818' \ --header 'rootkey: {{rootkey}}' \ --header 'Content-Type: application/json' 会迁移全文检索表,时间较长,迁移期间全文检索会失效,日志中会打印已经迁移的数据长度。
完整更新内容 link 新增 - 支持通过 JSON 配置直接创建应用。 新增 - 支持通过 CURL 脚本快速创建 HTTP 插件。 新增 - 商业版支持部门架构权限模式。 新增 - 支持配置自定跨域安全策略,默认全开。 新增 - 补充私有部署,模型问题排查文档。 优化 - HTTP Body 增加特殊处理,解决字符串变量带换行时无法解析问题。 优化 - 分享链接随机生成用户头像。 优化 - 图片上传安全校验。并增加头像图片唯一存储,确保不会累计存储。 优化 - Mongo 全文索引表分离。 优化 - 知识库检索查询语句合并,同时减少查库数量。 优化 - 文件编码检测,减少 CSV 文件乱码概率。 优化 - 异步读取文件内容,减少进程阻塞。 优化 - 文件阅读,HTML 直接下载,不允许在线阅读。 修复 - HTML 文件上传,base64 图片无法自动转图片链接。 修复 - 插件计费错误。 V4.8.17(包含升级脚本) Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/4817/ 更新指南 link1. 更新镜像: link 更新 fastgpt 镜像 tag: v4.8.17-fix-title 更新 fastgpt-pro 商业版镜像 tag: v4.8.17 Sandbox 镜像无需更新 2. 运行升级脚本 link从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 rootkey;{{host}} 替换成FastGPT 域名。
curl --location --request POST 'https://{{host}}/api/admin/initv4817' \ --header 'rootkey: {{rootkey}}' \ --header 'Content-Type: application/json' 会将用户绑定的 OpenAI 账号移动到团队中。
diff --git a/docs/guide/knowledge_base/api_dataset/index.html b/docs/guide/knowledge_base/api_dataset/index.html
index ac9ffdc2a51c..21415e4fe879 100644
--- a/docs/guide/knowledge_base/api_dataset/index.html
+++ b/docs/guide/knowledge_base/api_dataset/index.html
@@ -50,8 +50,8 @@
updateTime: Date;
createTime: Date;
}
- 1. 获取文件树 link
parentId - 父级 id,可选,或者 null。 searchKey - 检索词,可选 1. 获取文件树 link
parentId - 父级 id,可选,或者 null。 searchKey - 检索词,可选
curl --location --request POST '{{baseURL}}/v1/file/list' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
@@ -59,7 +59,7 @@
"parentId": null,
"searchKey": ""
}'
-
{
"code": 200,
"success": true,
@@ -75,12 +75,12 @@
}
]
}
- 2. 获取单个文件内容(文本内容或访问链接) link 2. 获取单个文件内容(文本内容或访问链接) link
curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
--header 'Authorization: Bearer {{authorization}}'
-
{
"code": 200,
"success": true,
@@ -90,11 +90,11 @@
"previewUrl": "xxxx"
}
}
-
二选一返回,如果同时返回则 content 优先级更高。
content - 文件内容,直接拿来用。 previewUrl - 文件链接,系统会请求该地址获取文件内容。 3. 获取文件阅读链接(用于查看原文) link id 为文件的 id。
二选一返回,如果同时返回则 content 优先级更高。
content - 文件内容,直接拿来用。 previewUrl - 文件链接,系统会请求该地址获取文件内容。 3. 获取文件阅读链接(用于查看原文) link id 为文件的 id。
curl --location --request GET '{{baseURL}}/v1/file/read?id=xx' \
--header 'Authorization: Bearer {{authorization}}'
-
{
"code": 200,
"success": true,
diff --git a/docs/guide/workbench/workflow/http/index.html b/docs/guide/workbench/workflow/http/index.html
index 3c161c7afe22..238fe46009d2 100644
--- a/docs/guide/workbench/workflow/http/index.html
+++ b/docs/guide/workbench/workflow/http/index.html
@@ -34,9 +34,9 @@
-Table of Contents
http
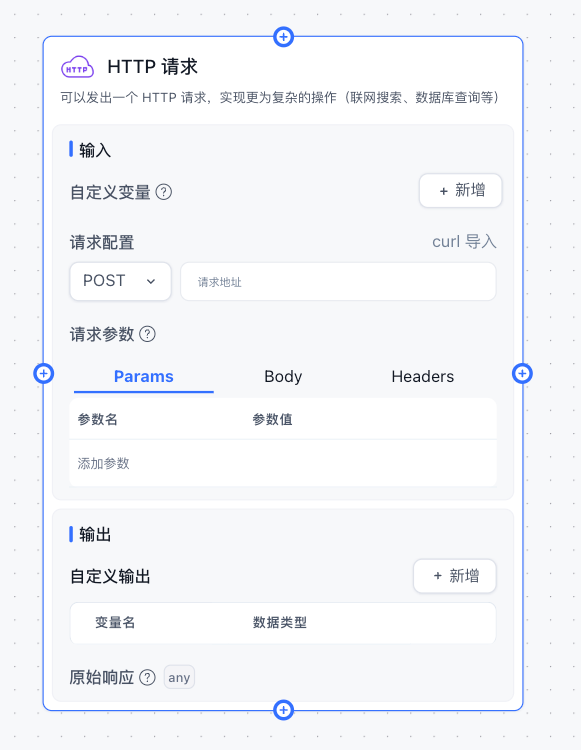
HTTP 请求 FastGPT HTTP 模块介绍
HTTP 模块会向对应的地址发送一个 HTTP 请求,实际操作与 Postman 和 ApiFox 这类直流工具使用差不多。
Params 为路径请求参数,GET请求中用的居多。 Body 为请求体,POST/PUT请求中用的居多。 Headers 为请求头,用于传递一些特殊的信息。 自定义变量中可以接收前方节点的输出作为变量 3 种数据中均可以通过 {{}} 来引用变量。 url 也可以通过 {{}} 来引用变量。 变量来自于全局变量、系统变量、前方节点输出 你可以将鼠标放置在请求参数旁边的问号中,里面会提示你可用的变量。
appId: 应用的ID chatId: 当前对话的ID,测试模式下不存在。 responseChatItemId: 当前对话中,响应的消息ID,测试模式下不存在。 variables: 当前对话的全局变量。 cTime: 当前时间。 histories: 历史记录(默认最多取10条,无法修改长度) 不多描述,使用方法和Postman, ApiFox 基本一致。
可通过 {{key}} 来引入变量。例如:
key value appId {{appId}} Authorization Bearer {{token}}
只有特定请求类型下会生效。
可以写一个自定义的 Json,并通过 {{key}} 来引入变量。例如:
http
HTTP 请求 FastGPT HTTP 模块介绍
HTTP 模块会向对应的地址发送一个 HTTP 请求,实际操作与 Postman 和 ApiFox 这类直流工具使用差不多。
Params 为路径请求参数,GET请求中用的居多。 Body 为请求体,POST/PUT请求中用的居多。 Headers 为请求头,用于传递一些特殊的信息。 自定义变量中可以接收前方节点的输出作为变量 3 种数据中均可以通过 {{}} 来引用变量。 url 也可以通过 {{}} 来引用变量。 变量来自于全局变量、系统变量、前方节点输出 你可以将鼠标放置在请求参数旁边的问号中,里面会提示你可用的变量。
appId: 应用的ID chatId: 当前对话的ID,测试模式下不存在。 responseChatItemId: 当前对话中,响应的消息ID,测试模式下不存在。 variables: 当前对话的全局变量。 cTime: 当前时间。 histories: 历史记录(默认最多取10条,无法修改长度) 不多描述,使用方法和Postman, ApiFox 基本一致。
可通过 {{key}} 来引入变量。例如:
key value appId {{appId}} Authorization Bearer {{token}}
只有特定请求类型下会生效。
可以写一个自定义的 Json,并通过 {{key}} 来引入变量。例如:
{
"string": "字符串",
"number": 123,
@@ -47,7 +47,7 @@
"url": "https://tryfastgpt.ai"
}
}
- 注意,在 Body 中,你如果引用字符串,则需要加上"",例如:"{{string}}"。
注意,在 Body 中,你如果引用字符串,则需要加上"",例如:"{{string}}"。
{
"string": "{{string}}",
"token": "Bearer {{string}}",
@@ -57,7 +57,7 @@
"array2": {{array}},
"object": {{obj}}
}
-
{
"string": "字符串",
"token": "Bearer 字符串",
@@ -70,8 +70,8 @@
"url": "https://tryfastgpt.ai"
}
}
- 从图中可以看出,FastGPT可以添加多个返回值,这个返回值并不代表接口的返回值,而是代表如何解析接口返回值,可以通过 JSON path 的语法,来提取接口响应的值。
语法可以参考: https://github.com/JSONPath-Plus/JSONPath?tab=readme-ov-file
从图中可以看出,FastGPT可以添加多个返回值,这个返回值并不代表接口的返回值,而是代表如何解析接口返回值,可以通过 JSON path 的语法,来提取接口响应的值。
语法可以参考: https://github.com/JSONPath-Plus/JSONPath?tab=readme-ov-file
{
"message": "测试",
"data":{
@@ -89,7 +89,7 @@
"psw": "xxx"
}
}
-
{
"$.message": "测试",
"$.data.user": { "name": "xxx", "age": 12 },
diff --git a/index.xml b/index.xml
index e02428cd6a0e..e653757967b5 100644
--- a/index.xml
+++ b/index.xml
@@ -475,7 +475,7 @@ docker exec -it fastgpt sh mkdir -p /data/backup 建好后,未来导出mongo
mkdir -p /fastgpt/data/backup 准备好后,后续上传
### 新fastgpt环境【B】中也需要建一个,比如/fastgpt/mongobackup目录,注意不要在fastgpt/data目录下建立目录 mkdir -p /fastgpt/mongobackup
###2. 正题开始,从fastgpt老环境【A】中导出数据 进入A环境,使用mongodump 导出mongo数据库。 #### 2.Docker 数据库迁移(无脑操作) Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/migration/docker_db/ Copy文件 linkDocker 部署数据库都会通过 volume 挂载本地的目录进入容器,如果要迁移,直接复制这些目录即可。
-PG 数据: pg/data Mongo 数据: mongo/data V4.8.18 Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/4818/ 更新指南 link1. 更新镜像: link 更新 fastgpt 镜像 tag: v4.8.18 更新 fastgpt-pro 商业版镜像 tag: v4.8.18 Sandbox 镜像无需更新 2. 运行升级脚本 link从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 rootkey;{{host}} 替换成FastGPT 域名。
+PG 数据: pg/data Mongo 数据: mongo/data V4.8.18 Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/4818/ 更新指南 link1. 更新镜像: link 更新 fastgpt 镜像 tag: v4.8.18-fix 更新 fastgpt-pro 商业版镜像 tag: v4.8.18-fix Sandbox 镜像无需更新 2. 运行升级脚本 link从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 rootkey;{{host}} 替换成FastGPT 域名。
curl --location --request POST 'https://{{host}}/api/admin/initv4818' \ --header 'rootkey: {{rootkey}}' \ --header 'Content-Type: application/json' 会迁移全文检索表,时间较长,迁移期间全文检索会失效,日志中会打印已经迁移的数据长度。
完整更新内容 link 新增 - 支持通过 JSON 配置直接创建应用。 新增 - 支持通过 CURL 脚本快速创建 HTTP 插件。 新增 - 商业版支持部门架构权限模式。 新增 - 支持配置自定跨域安全策略,默认全开。 新增 - 补充私有部署,模型问题排查文档。 优化 - HTTP Body 增加特殊处理,解决字符串变量带换行时无法解析问题。 优化 - 分享链接随机生成用户头像。 优化 - 图片上传安全校验。并增加头像图片唯一存储,确保不会累计存储。 优化 - Mongo 全文索引表分离。 优化 - 知识库检索查询语句合并,同时减少查库数量。 优化 - 文件编码检测,减少 CSV 文件乱码概率。 优化 - 异步读取文件内容,减少进程阻塞。 优化 - 文件阅读,HTML 直接下载,不允许在线阅读。 修复 - HTML 文件上传,base64 图片无法自动转图片链接。 修复 - 插件计费错误。 V4.8.17(包含升级脚本) Mon, 01 Jan 0001 00:00:00 +0000 https://doc.tryfastgpt.ai/docs/development/upgrading/4817/ 更新指南 link1. 更新镜像: link 更新 fastgpt 镜像 tag: v4.8.17-fix-title 更新 fastgpt-pro 商业版镜像 tag: v4.8.17 Sandbox 镜像无需更新 2. 运行升级脚本 link从任意终端,发起 1 个 HTTP 请求。其中 {{rootkey}} 替换成环境变量里的 rootkey;{{host}} 替换成FastGPT 域名。
curl --location --request POST 'https://{{host}}/api/admin/initv4817' \ --header 'rootkey: {{rootkey}}' \ --header 'Content-Type: application/json' 会将用户绑定的 OpenAI 账号移动到团队中。