Speech to text, text to Speech - STTTTS - S4TS
ElevenLabs S4TS is a PySide6 (Qt) application that does speech to text and then text to speech using eleven labs. The automatic speech recognition (ASR) model used for this application is OpenAI’s Whisper.
At startup, the application will use the whisper-base model for faster audio transcription. However, if your hardware supports cuda, you can change it to whisper-medium by checking Use Medium Model. ElevenLabs S4TS will automatically use cuda if your hardware supports cuda and your PyTorch is installed to support it.
-
Make sure Python 3.9 > is installed
-
Make your
condaorpipenv -
Activate the virtual environment
-
Install
PyTorchby following the instructions here -
Install ElevenLabs S4TS dependencies
# Pip pip install -U -r requirements.txt # Conda conda install pip pip install -U -r requirements.txt
Once you have all of the dependencies installed. We simply need to run ui.py by doing the following (assuming the virtual environment is activated):
python3 ui.py
- First of all, you need to have a plan for ElevenLabs. It does not matter what plan tier you have as long as you have one. Go here to check out plans that they offer.
- When you’re signed up, go to your profile icon on the top left and click profile and copy your API Key.
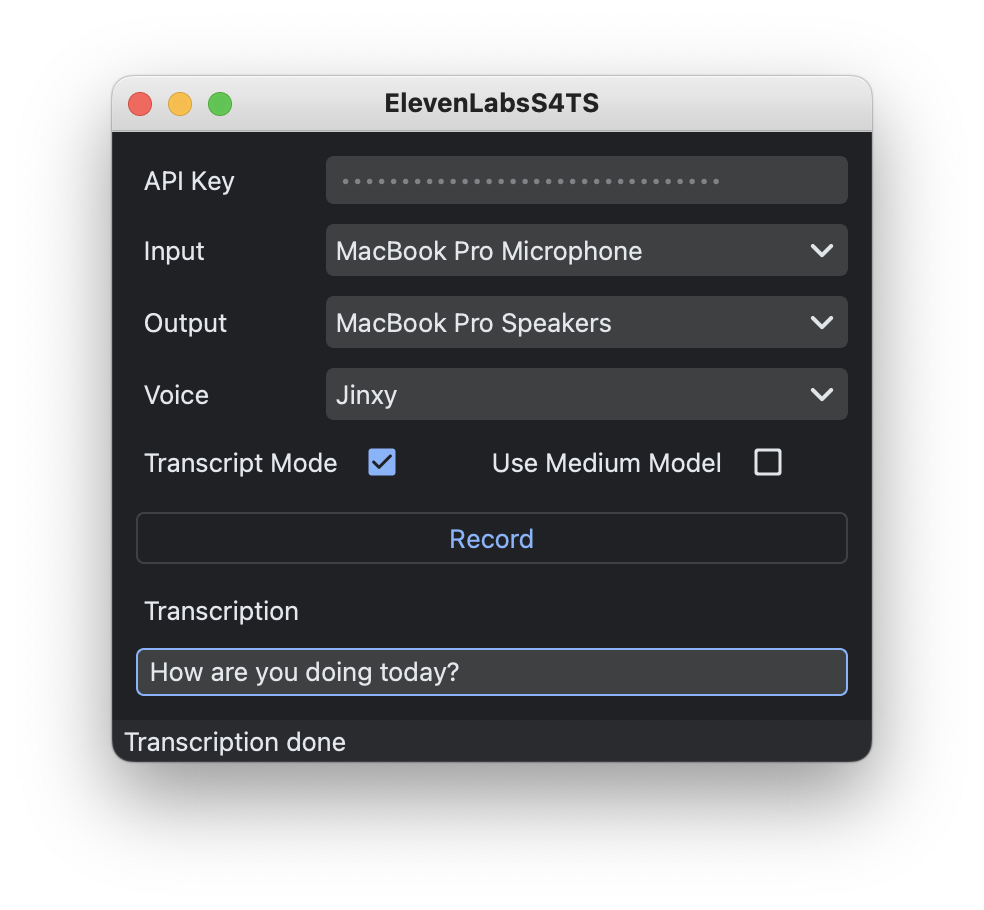
- Paste your API key on the input field labeled
API Keyon the window - Select your desired input and output device
- Select desired ElevenLabs voice
- Hold the Record button and speak
- Once released, the audio will be processed using
whisperfor transcription - After transcription, the text will be sent to ElevenLabs using their API
- The request returns an audio data that ElevenLabsS4TS plays through the set output device
- Package application
- Add ability to voice clone using mic