Forecasting Time Series
-
Train Set / Test Set의 Distribution이 다름
-
Target Population의 Distribution이 계속 변하는데, 그 변하는 Distribution을 추적하여 새로 학습하여야 함
-
Cat Classification문제에에서 Distribution of cat picture features은 stationary distribution
The visual properties of cats are stable over time, so when we train a neural network to recognize pictures of cats, an implicit assumption is that the features that define cats are going to remain the same for the foreseeable future. We don’t expect cats to look different next week, or next year, or even ten years from now. In statistical parlance, we say that the distribution of cat picture features is a stationary distribution, meaning that its properties such as its mean and standard deviation remain the same over time.
- Forecasting문제에서 Australian Beer Sales는 non-stationary distribution
Well for time series, it is almost always the case that the development data set and the production data set are not from the same distribution, because real world business time series (such as the Australian beer sales) data are not stationary, and the statistical properties of your distribution will keep shifting as new actuals come in.
-
해결방법? : Continual Learning(제가 아는 워딩)으로 모델을 계속 업데이트
-
다만 저 포스트를 쓴 사람은 Continuous Learning(포스트에서 쓴 워딩)과는 다른 컨셉이라고 이야기함.
-
작성자피셜 : Continuous Learning은 모델을 새 데이터로 업데이트하는 것이고, 여기서는 새 Forecast를 만들고자 할때마다 Scratch에서부터 아예 새 모델을 만든다
Note that this is not the same as continuous learning, where an already trained model is updated as new data comes in. You are actually retraining a new model from scratch everytime you want to generate a new forecast
- Cross Validation 사용 불가 (미래를 학습하여 과거를 예측?)
- Alternative Validation Techniques
- Walk Forward Optimization

- Nested Cross Validation
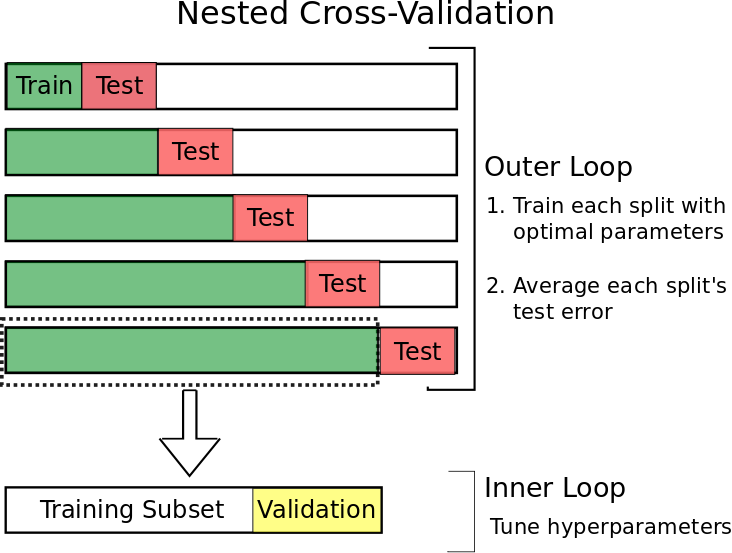
- Non-stationary한 Distribution을 다루는 Forecasting문제 특성상 틀릴 가능성이 크다
- 그래서 Test가 Out-of-Distribution Sample인지 확인하여 Uncertainty를 제공하자
- 모델 자체의 성능보다는 모델을 실제로 사용할때의 Usability에 대한 내용인듯
- 이전에 조사했던 Out of Distribution Detection을 활용하거나, Novelty Detection으로 Uncertainty를 보여주자
- Train Dist.와 Test Dist.의 KL Divergence로 Test score과의 관계를 검증하려 시도해보았으나, Test Score가 크게 떨어질때(Test Distribution이 크게 다를것으로 추정될때) KLD는 크게 변하지 않았음
- 빠르게 적용하려면, 간단하게는 Test Set의 각 Sample들이 Train Distribution의 mean으로부터 몇 시그마만큼 떨어져있는지로 사용할수도 있을듯
- 결론 : Test Sample에 대한 Novelty Score(~= Uncertainty)를 같이 제공하자!
- Seasonality, Trend, Cycle등을 학습하기 위한 Variable 다음과 같이 제시함
- Dummy variables
- Similar to how seasonality can be added as a binary feature, other features can be added in binary format to the model. You can add holidays, special events, marketing campaigns, whether a value is outlier or not, etc. However, you should remember that these variables need to have definite patterns.
- Number of days
- These can be easily calculated even for future months/quarters and may affect forecasts, especially for financial data. Here you can include:
- Number of days
- Number of trading days
- Number of weekend days
- …and so on
- Lagged values
- You can include lagged values of the variable as predictors. Some models like ARIMA, Vector Autoregression (VAR), or Autoregressive Neural Networks (NNAR) work this way.
- Dummy variables
At first glance, you might think that this is a drawback. But in reality, there are some benefits to having small- to medium-sized time series:
- Drawbacks from the bigger Dataset
- 모델은 데이터를 설명할만큼 충분히 복잡해야함
- 시간에 따라 Distribution이 변하는 것과 동시에, 시간에 따라 x->y의 관계도 변할수 있음. 이 경우에 모델은 같은 x에서 서로 다른 두가지 y를 보게 됨. 둘중에 하나는 반드시 틀릴수밖에 없고 학습을 방해하는 원인이 됨.
- 결국 모델은 아래와 같은 상반된 목표를 가지게 되고, Hyperparameter에 따른 Trade-off가 존재
-
- 최신의 Distribution, x->y 관계를 학습해야 함
-
- 오래된 Distribution, 현재에 유효하지 않은 x->y 관계를 잊어버려야 함
-
- Train set의 길이는 Test Data를 충분히 설명할만큼 모델을 Generalize할수 있어야 함. (= Train Set의 길이는 충분히 길어야 함)
-
-
MAE기반의 Metrics
-
R2 Square를 안 쓰는 이유?
- 예측 총량(평균값)을 맞추면 R2 Score가 0
- 개별 Prediction을 전부다 맞추면 R2 Score가 1
- 예측 총량조차 맞추지 못하면 ( mean(prediction) != mean(actual) ) R2 Score가 -
- Forecasting을 하면서 미래의 총량을 맞추는것도 쉽지 않기 때문에 R2 Score 음수를 자주 보게된다
- 그래서 MAE기반의 Metric을 쓰는듯
- In Sample Train Set, In Sample Test Set을 가지고 있을때는 적어도 평균으로 미는 성능이 보장되고, 이때 평균으로 미는 성능보다 더 잘하느냐가 중요한 이슈
- 다만 Forecasting은 In Sample Train Set, Out Sample Test Set인 경우가 많다.
- 결론 : R2 Score가 0만 넘겨도 어쨌든 총량은 맞추는 Forecasting 모델이다
-
MAE가 더 중요한 경우?
- 모든 prediction이 actual value보다 0.001씩 높을 경우 R2 score는 마이너스 ( sum(prediction) != sum(actual) )
- MAE는 매우 작을것
- 이것은 예측성능이 떨어지는 모델인가?
- 결론 : Objective (총량이 중요 vs 적은 에러가 중요) 에 따라 적합한 Measure가 다를수 있다