
This guide explains how to gather hotel listings, prices, and amenities from Google Travel using either Selenium methods or Bright Data’s APIs.
- Prerequisites
- What To Extract From Google Travel
- Extracting The Data With Selenium
- Extracting the Data With Bright Data’s Travel API
- Bright Data’s Alternative Solutions
To scrape travel data, you’re going to need Python and either Selenium, Requests, or AIOHTTP modules. With Selenium, you’ll scrape hotel information straight from Google Travel. With Requests and AIOHTTP, you’ll use Bright Data’s Booking.com API.
If you’re using Selenium, make sure you have webdriver installed. If you’re unfamiliar with Selenium, take a look at this guide to get acquainted quickly.
Install Selenium:
pip install selenium
Install Requests:
pip install requests
Install AIOHTTP:
pip install aiohttpAll of the hotel results come embedded in a custom c-wiz element from Google Travel.
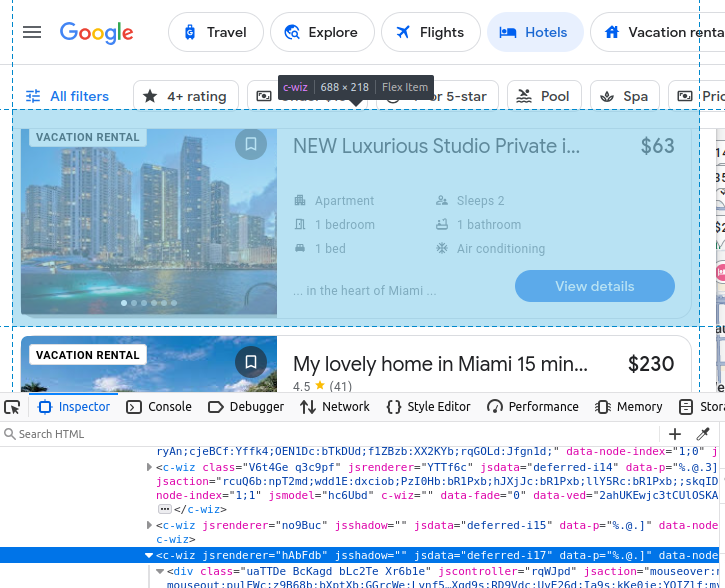
However, there are many c-wiz elements on the page. Each hotel card contains an a element directly descended from a div and this c-wiz element. We can write a CSS selector to find all a tags descended from these elements: c-wiz > div > a.
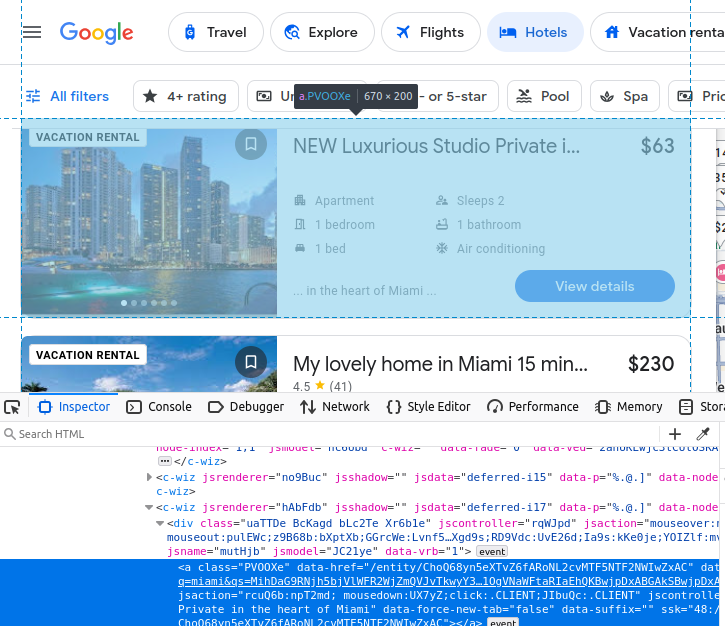
The name of the listing comes embedded in an h2.
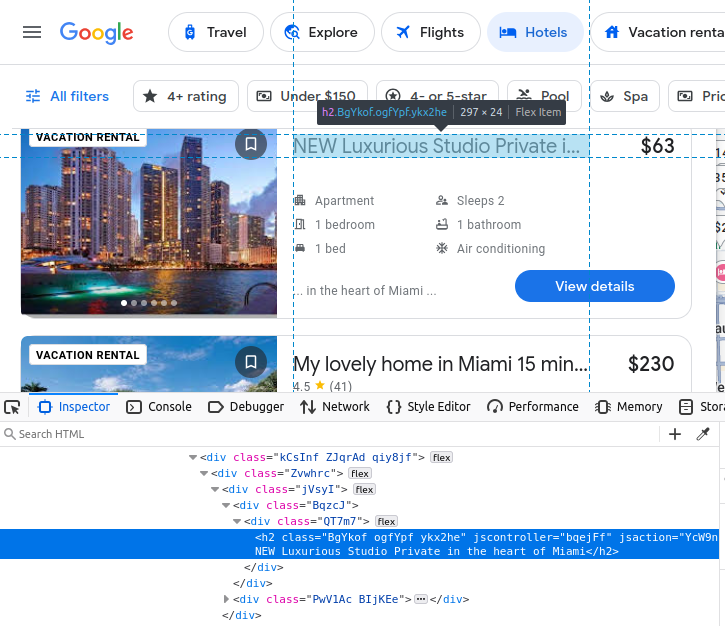
Our price comes embedded in a span.
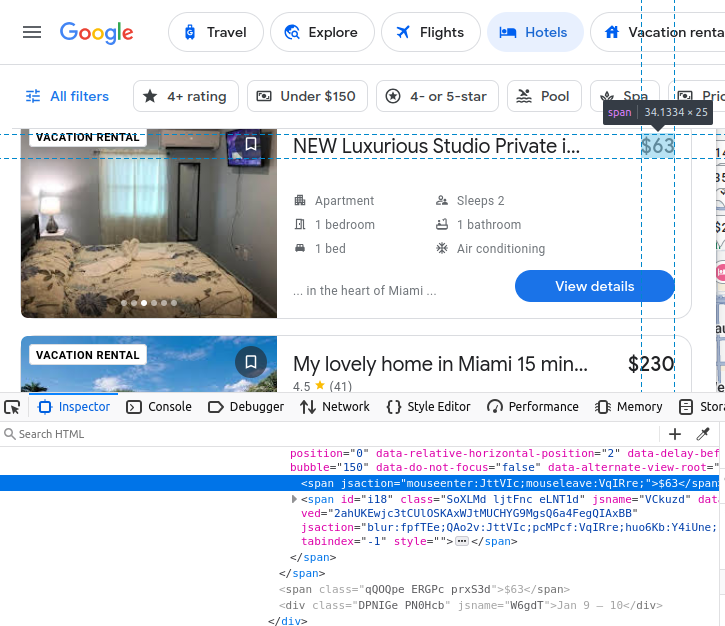
Our amenities are embedded in li (list) elements.
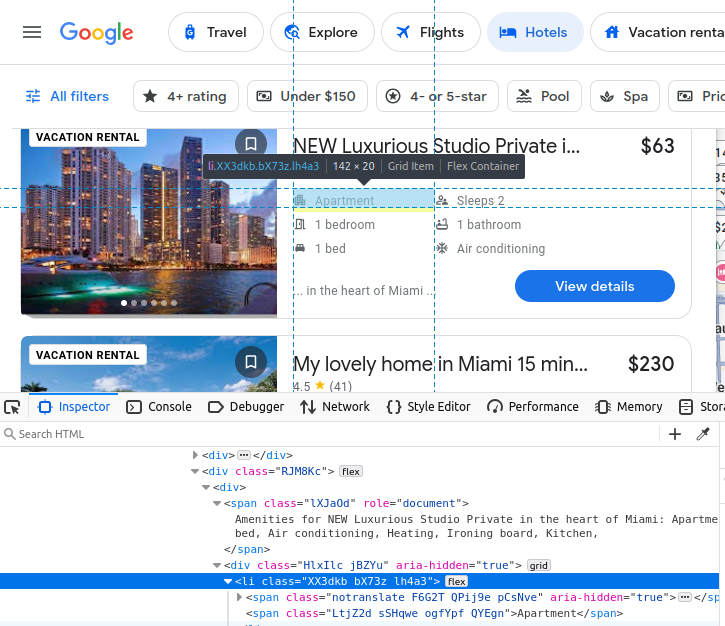
After finding a hotel card, we can extract all of the aforementioned data from it.
Extracting this data with Selenium is relatively straightforward once you know what to look for. However, Google Travel loads the results dynamically, which makes it a delicate process held together by preconfigured waits, mouse clicks, and custom windows.
Here is the full Python script:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import json
from time import sleep
OPTIONS = webdriver.ChromeOptions()
OPTIONS.add_argument("--headless")
OPTIONS.add_argument("--window-size=1920,1080")
def scrape_hotels(location, pages=5):
driver = webdriver.Chrome(options=OPTIONS)
actions = ActionChains(driver)
url = f"https://www.google.com/travel/search?q={location}"
driver.get(url)
done = False
found_hotels = []
page = 1
result_number = 1
while page <= pages:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(5)
hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")
print(f"-----------------PAGE {page}------------------")
print("FOUND ITEMS: ", len(hotel_links))
for hotel_link in hotel_links:
hotel_card = hotel_link.find_element(By.XPATH, "..")
try:
info = {}
info["url"] = hotel_link.get_attribute("href")
info["rating"] = 0.0
info["price"] = "n/a"
info["name"] = hotel_card.find_element(By.CSS_SELECTOR, "h2").text
price_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span")
info["amenities"] = []
amenities_holders = hotel_card.find_elements(By.CSS_SELECTOR, "li")
for amenity in amenities_holders:
info["amenities"].append(amenity.text)
if "DEAL" in price_holder[0].text or "PRICE" in price_holder[0].text:
if price_holder[1].text[0] == "$":
info["price"] = price_holder[1].text
else:
info["price"] = price_holder[0].text
rating_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span[role='img']")
if rating_holder:
info["rating"] = float(rating_holder[0].get_attribute("aria-label").split(" ")[0])
info["result_number"] = result_number
if info not in found_hotels:
found_hotels.append(info)
result_number+=1
except:
continue
print("Scraped Total:", len(found_hotels))
next_button = driver.find_elements(By.XPATH, "//span[text()='Next']")
if next_button:
print("next button found!")
sleep(1)
actions.move_to_element(next_button[0]).click().perform()
page+=1
sleep(5)
else:
done = True
driver.quit()
with open("scraped-hotels.json", "w") as file:
json.dump(found_hotels, file, indent=4)
if __name__ == "__main__":
PAGES = 2
scrape_hotels("miami", pages=PAGES)Let's review what the script does step by step:
- First, we create an instance of
ChromeOptions. We use this to add our--headlessand--window-size=1920,1080arguments.
Note
Without the custom window size, the results would not load properly, and we would end up scraping the same results over and over again.
-
When we launch the browser, we use the keyword argument,
options=OPTIONS. This launches Chrome with our custom options. -
ActionChains(driver)gives us anActionChainsinstance. We use this later in our script to move the cursor to theNextbutton and then click on it. -
We use a
whileloop to contain our runtime. Once the scrape has finished, we’ll exit this loop. -
hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")gives us all of the hotel links on the page. We find their parent elements using their xpath:hotel_card = hotel_link.find_element(By.XPATH, ".."). -
We go through and extract all the individual bits of data we looked at earlier:
- url:
hotel_link.get_attribute("href") - name:
hotel_card.find_element(By.CSS_SELECTOR, "h2").text - When looking for the price, there are sometimes additional elements in the card such as
DEALandGREAT PRICE. To ensure that we’re always getting the right price, we extract thespanelements in an array. If the array contains these words, we take the second element (price_holder[1].text) instead of the first one (price_holder[0].text) - We also use the
find_elements()method when looking for the rating. If there is no rating present, we give it a default value ofn/a. hotel_card.find_elements(By.CSS_SELECTOR, "li")yields our amenity holders. We extract each of them using theirtextattribute.
- url:
-
We continue this loop until we’ve scraped all of our desired pages. Once we’ve got our data, we set
donetoTrueand exit the loop. -
We close the browser and use
json.dump()to save all of our scraped data to a JSON file.
If you don't want to depend on a scraper or deal with selectors and locators, you can use our travel data or extract hotel data using our Booking.com API. Two methods to do it are the requests module and the AIOHTTP library.
The code below sets you up with the Booking.com API. Simply enter your API key, travel location, check-in date and check-out date. First, it makes a request to the API to generate the data. Then, it repeatedly checks on the data every 10 seconds until our report is ready. Once we’ve received our data, we save it in a JSON file.
import requests
import json
import time
def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/datasets/v3/trigger"
#booking.com dataset
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
auth_token = api_key
#
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
response = requests.post(endpoint, headers=headers, json=payload)
if response.status_code == 200:
print("Request successful. Response:")
print(json.dumps(response.json(), indent=4))
return response.json()["snapshot_id"]
else:
print(f"Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
#create the snapshot url
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
#write the snapshot to a new json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
break
elif response.status_code == 202:
print("Snapshot is not ready yet. Retrying in 10 seconds...")
else:
print(f"Error: {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "your-bright-data-api-key"
LOCATION = "Miami"
CHECK_IN = "2025-02-01T00:00:00.000Z"
CHECK_OUT = "2025-02-02T00:00:00.000Z"
DATES = {
"check_in": CHECK_IN,
"check_out": CHECK_OUT
}
snapshot_id = get_bookings(API_KEY, LOCATION, DATES)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)get_bookings()takes yourAPI_KEY,LOCATIONandDATES. It then makes a request for the data and returns thesnapshot_id.- The
snapshot_idis required to retrieve the snapshot. - After the
snapshot_idhas been generated,poll_and_retrieve_snapshot()checks every 10 seconds to see if the data is ready. - Once the data is ready, we use
json.dump()to save it to a JSON file.
When you run the code, you should see something similar to this in your terminal.
Request successful. Response:
{
"snapshot_id": "s_m5moyblm1wikx4ntot"
}
Polling snapshot for ID: s_m5moyblm1wikx4ntot...
Snapshot is not ready yet. Retrying in 10 seconds...
Snapshot is not ready yet. Retrying in 10 seconds...
Snapshot is not ready yet. Retrying in 10 seconds...
Snapshot is not ready yet. Retrying in 10 seconds...
Snapshot is ready. Downloading...
Snapshot saved to snapshot-data.json
Then you’ll get a JSON file full of objects like this.
{
"input": {
"url": "https://www.booking.com",
"location": "Miami",
"check_in": "2025-02-01T00:00:00.000Z",
"check_out": "2025-02-02T00:00:00.000Z",
"adults": 2,
"rooms": 1
},
"url": "https://www.booking.com/hotel/us/ramada-plaze-by-wyndham-marco-polo-beach-resort.html?checkin=2025-02-01&checkout=2025-02-02&group_adults=2&no_rooms=1&group_children=",
"location": "Miami",
"check_in": "2025-02-01T00:00:00.000Z",
"check_out": "2025-02-02T00:00:00.000Z",
"adults": 2,
"children": null,
"rooms": 1,
"id": "55989",
"title": "Ramada Plaza by Wyndham Marco Polo Beach Resort",
"address": "19201 Collins Avenue",
"city": "Sunny Isles Beach (Florida)",
"review_score": 6.2,
"review_count": "1788",
"image": "https://cf.bstatic.com/xdata/images/hotel/square600/414501733.webp?k=4c14cb1ec5373f40ee83d901f2dc9611bb0df76490f3673f94dfaae8a39988d8&o=",
"final_price": 217,
"original_price": 217,
"currency": "USD",
"tax_description": null,
"nb_livingrooms": 0,
"nb_kitchens": 0,
"nb_bedrooms": 0,
"nb_all_beds": 2,
"full_location": {
"description": "This is the straight-line distance on the map. Actual travel distance may vary.",
"main_distance": "11.4 miles from downtown",
"display_location": "Miami Beach",
"beach_distance": "Beachfront",
"nearby_beach_names": []
},
"no_prepayment": false,
"free_cancellation": true,
"property_sustainability": {
"is_sustainable": false,
"level_id": "L0",
"facilities": [
"436",
"490",
"492",
"496",
"506"
]
},
"timestamp": "2025-01-07T16:43:24.954Z"
},With the AIOHTTP library, this process can become faster because we can trigger, poll, and download multiple datasets simultaneously. The code below builds on the concepts from the Requests example above, but instead uses aiohttp.ClientSession() to make multiple requests asynchronously.
import aiohttp
import asyncio
import json
async def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/datasets/v3/trigger"
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
async with aiohttp.ClientSession(headers=headers) as session:
async with session.post(endpoint, json=payload) as response:
if response.status == 200:
response_data = await response.json()
print(f"Request successful for location: {location}. Response:")
print(json.dumps(response_data, indent=4))
return response_data["snapshot_id"]
else:
print(f"Error for location: {location}. Status: {response.status}")
print(await response.text())
return None
async def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file):
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
async with aiohttp.ClientSession(headers=headers) as session:
while True:
async with session.get(snapshot_url) as response:
if response.status == 200:
print(f"Snapshot for {output_file} is ready. Downloading...")
snapshot_data = await response.json()
# Save snapshot data to a file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
break
elif response.status == 202:
print(f"Snapshot for {output_file} is not ready yet. Retrying in 10 seconds...")
else:
print(f"Error polling snapshot for {output_file}. Status: {response.status}")
print(await response.text())
break
await asyncio.sleep(10)
async def process_location(api_key, location, dates):
snapshot_id = await get_bookings(api_key, location, dates)
if snapshot_id:
output_file = f"snapshot-{location.replace(' ', '_').lower()}.json"
await poll_and_retrieve_snapshot(api_key, snapshot_id, output_file)
async def main():
api_key = "your-bright-data-api-key"
locations = ["Miami", "Key West"]
dates = {
"check_in": "2025-02-01T00:00:00.000Z",
"check_out": "2025-02-02T00:00:00.000Z"
}
# Process all locations in parallel
tasks = [process_location(api_key, location, dates) for location in locations]
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main())- Both
get_bookings()andpoll_and_retrieve_snapshot()now use theaiohttp.ClientSessionobject to create async requests to the server. process_location()is used to process all data for a location.main()allows us to callprocess_location()on all locations simultaneously.
Here is the output:
Request successful for location: Miami. Response:
{
"snapshot_id": "s_m5mtmtv62hwhlpyazw"
}
Request successful for location: Key West. Response:
{
"snapshot_id": "s_m5mtmtv72gkkgxvdid"
}
Polling snapshot for ID: s_m5mtmtv62hwhlpyazw...
Polling snapshot for ID: s_m5mtmtv72gkkgxvdid...
Snapshot for snapshot-miami.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-miami.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-miami.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-miami.json is ready. Downloading...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot saved to snapshot-miami.json
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is ready. Downloading...
Snapshot saved to snapshot-key_west.json
Beyond the Web Scraper APIs, Bright Data provides ready-to-use datasets tailored to meet diverse needs. Among our most sought-after travel datasets are:
You can choose between fully managed or self-managed custom datasets, allowing you to extract data from any public website and customize it to your exact specifications.