Multi-label classification of real estate offices' amenities using Convolutional Neural Network (CNN)
Team: Petr Nguyen, Ilya Tsakunov, Peter Kachnic, Katerina Nekvindova, Adrian Harvan, Simona Dohova, Marco Vezzola
Within the course Trends in business analytics I (4IZ481) at Faculty of Informatics and Statistics, Prague University of Economics and Business, we had to introduce a business solution of unstructured data usage with partial implementation in Python. Our team came up with a business solution which combines both image processing and natural language processing.
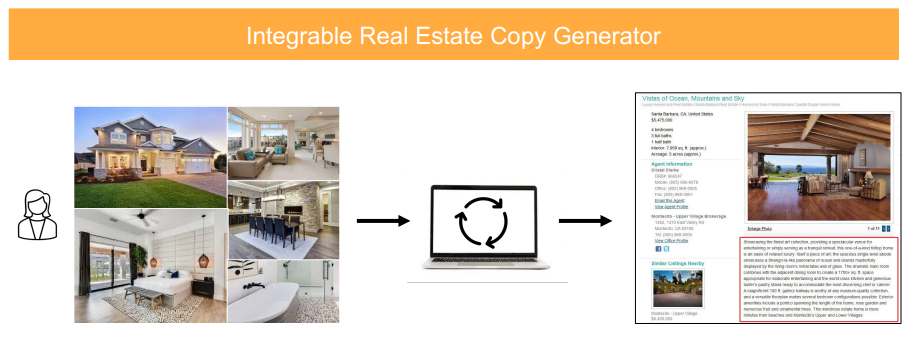
Particularly, based on our research, we introduced a model for object detection which helps to detect and recognize the real estates' amenities and then outputs a list of amenities which given real estate has, based on the provided real-estate pictures. Afterwards, such predicted amenities' lists are used as keywords for text generator of property listing within real-estate advertisement.
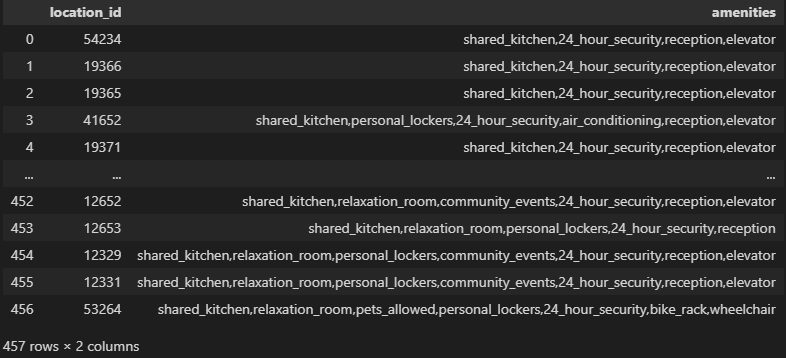
We were provided with web-scrapped dataset of German offices' pictures and CSV file with the annotations, which contains 457 offices and 15 types of amenities.
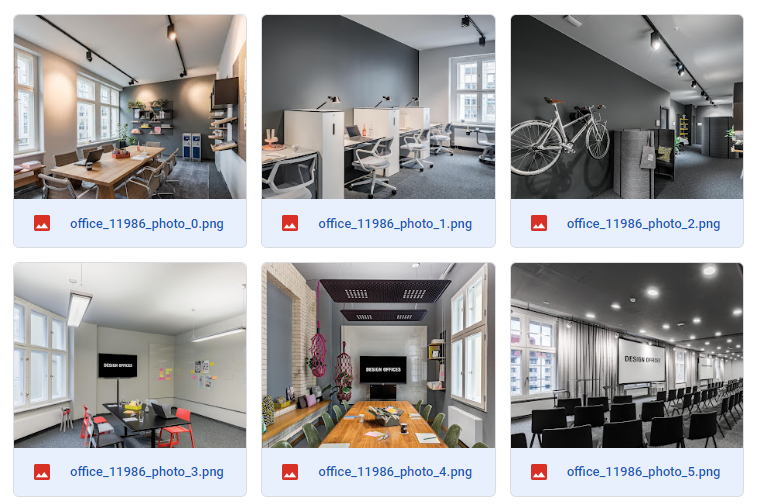
Our partial Python solution regarded an image processing of real-estate amenities using Keras and Tensorflow. After image processing such as loading the pictures as 3D arrays with further reshaping, normalization and tensor conversion, we split them into training set for model building and weight optimization, validation set for hyperparameter tuning and optimization, and test set for the model evaluation.
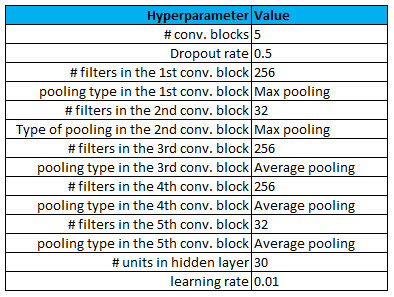
We developed a custom Convolutional Neural Network (CNN) for multi-label classification in order to predict a probability score for each amenity's occurrence of given office. We optimized CNN's hyperparameters with Bayesian Optimization while minimizing a binary cross entropy loss function, where we tuned:
- the number of convolutional blocks,
- the value of the filters within a single convolution,
- the type of the pooling (whether use Max Pooling or Average Pooling),
- the number of units in the dense layer,
- the value of the dropout rate in the dropout layer as a regularization constraint with respect to the overfitting,
- the value of the learning rate of stochastic gradient descent method, namely the Adaptive Moment Estimation (Adam) optimizer.
Such developed and optimized model also includes batch normalization layers and uses sigmoid function for multilabel-classification (assuming the predicted probabilities are independent) and is visualized below with following tuned hyperparameters.

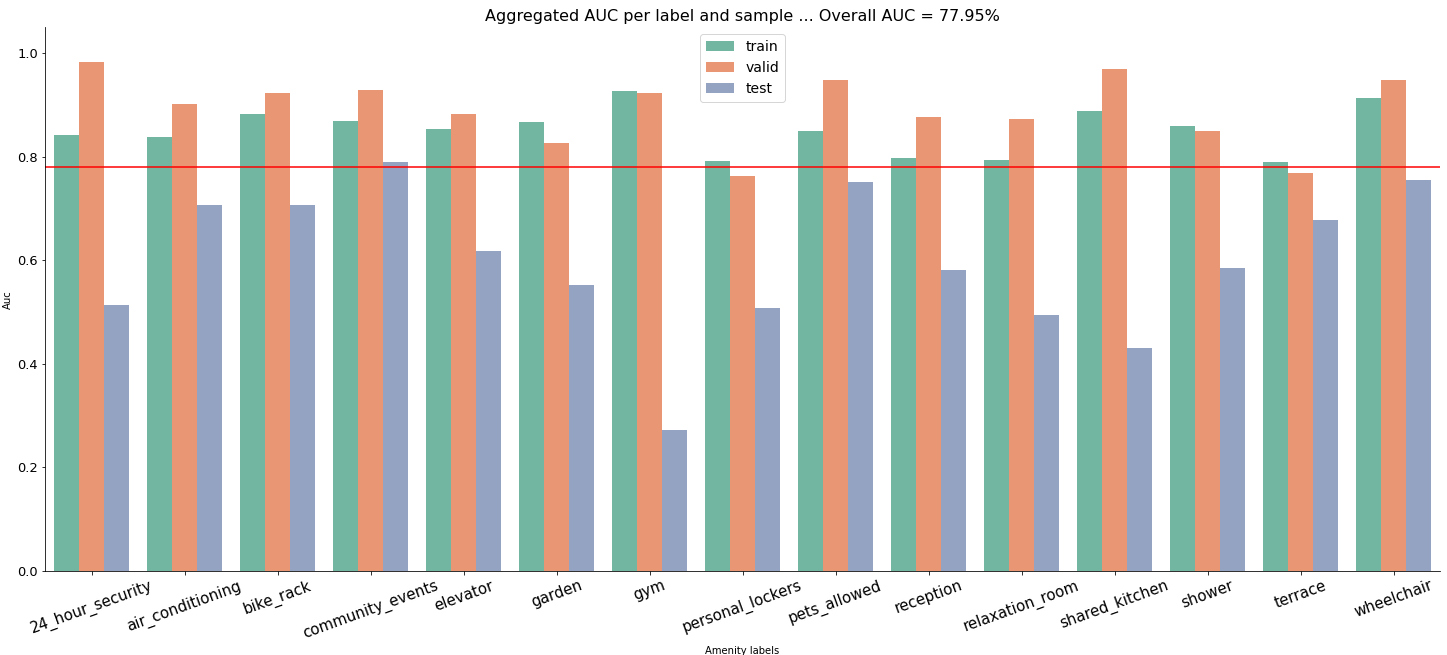
Within the evaluation, we averaged the predicted probabilities to get aggregated probabilities on the office level, which were then used for a classification of the amenities' occurrences. By taking the predicted amenities' occurrences (predicted labels) or the predicted probabilities and the actual amenities occurrences (true labels), we calculate overall metrics F1 score, accuracy, precision, recall or AUC. For instance, the following graph depicts an AUC scores' distribution across the amenities and samples.
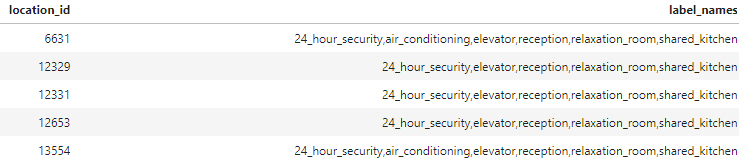
The main output of this project is a list of predicted amenities, which given offices should have. Such lists can be then used as an input, as already mentioned, for a text generator of property listing within real-estate advertisement.
For the further development, we recommend following:
- Use pictures with a better quality and higher resolution
- Proper pictures' selection - use only relevant pictures (we do not want model train on non-relevant pictures such as a picture of a building from the outside etc).
- Increase training and validation size (in order to increase model performance)
- Perform an image augmentation - especially for the offices' pictures having such amenities which do not occur that often in the dataset (in order to deal with imbalanced classes).
- Re-definition of amenities labels (some amenities are hardly observed from pictures).
- Choosing a different, ideally an optimal, threshold for classification of amenities' occurrences.
In conclusion, with respect to our business case for generating property listings of real estates based on provided photos, we deem our solution appropriate. If we implement the recommendations mentioned above, we would be able to increase model performance even more which would result in more accurate generated property listings. Thus, this would help to save time costs, improve SEO or increase sales in the real-estate sector using more efficient real-estate advertisement.