关于即刻热门推荐的爬虫与分析,爬取web端的热门推荐,每小时获取一次数据。对json数据进行清晰,进行二次挖掘和分析。在介绍主要工作之前,先对整个项目进行说明。
data/:存放的是需要查询的信息
- city_code.py: 城市编号查询,来源于constant.py
- region.sql: 城市经纬度位置查询,来源于region.sql
2019-06-16/:诸如此类的文件夹,为爬取到的json数据文件(由于误操作可能会有小部分数据缺失)
spider.py:爬虫文件,由于过于简单,故不介绍
example/:示例文件。2019-06-15-23.json:示例json文件;2019-06-15-23.xlsx:示例excel文件;map.xlsx:示例map文件;Thermal map.png:示例热力图
| 变量 | 说明 |
|---|---|
| likeCount | 点赞数 |
| repostCount | 分享数(此数据意义不理解,变化波动不大) |
| commentCount | 评论数 |
| shareCount | 分享数 |
| commentCount | 发贴用户的关注用户数 |
| id | 每个帖子独一无二的标识码 |
提取每个json文件的'topic', 'content', 'likeCount', 'repostCount', 'commentCount', 'shareCount',将其转换为excel表格。
将其放入每天的json文件夹中,绘制'likeCount', 'repostCount', 'commentCount', 'shareCount', 'followedCount'随时间变化的曲线。
- 统计所有文件夹下的json文件的出现频率高的话题圈
- 绘制某天所有topic的关注人数的柱状图
- 绘制所有日期文件夹下的topic的关注人数随时间变化的折线图
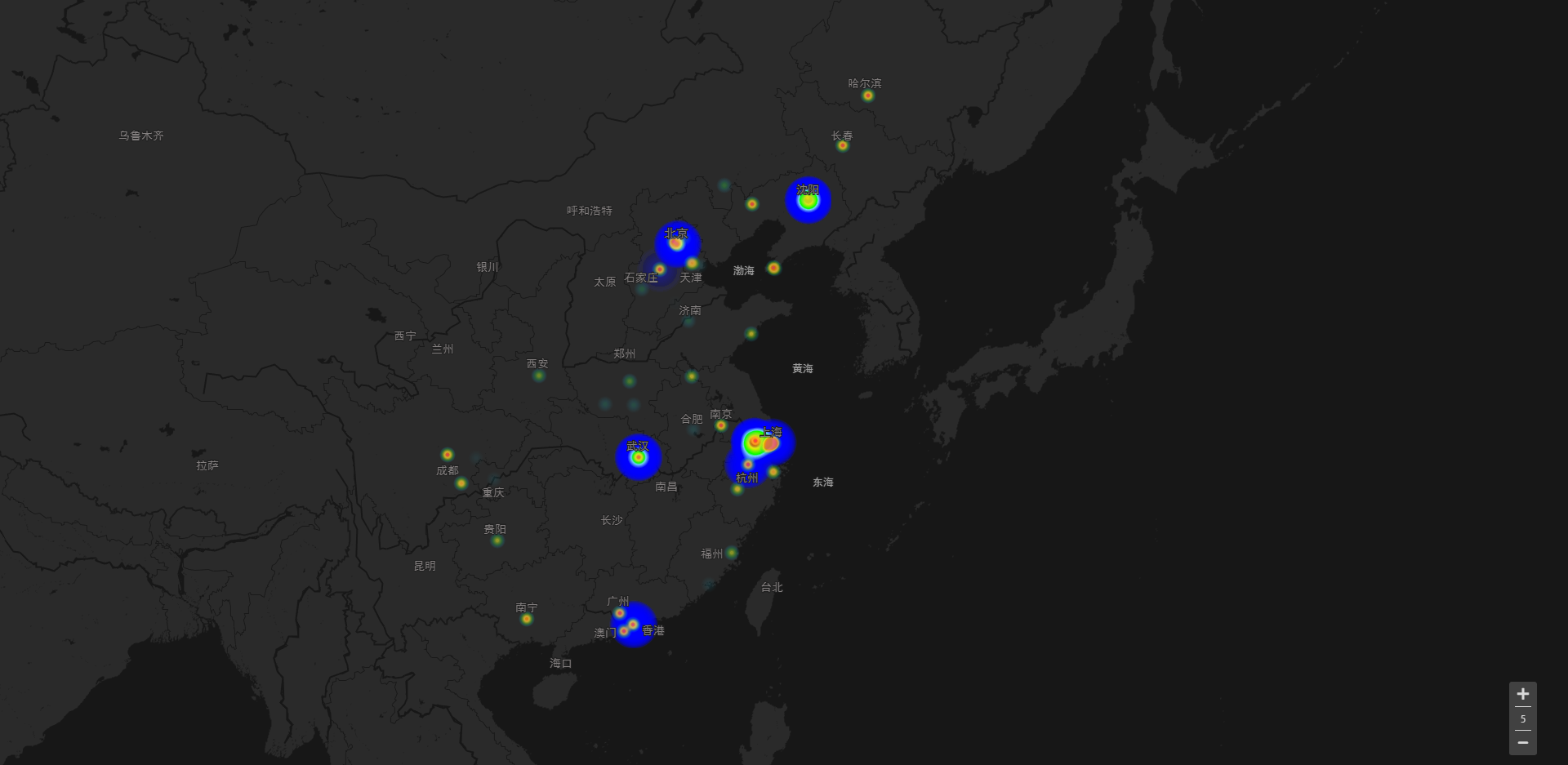
统计热门帖子的发帖地点,并由此得到绘制热力图数据(map.xlsx),根据高德平台绘制热力图。
统计发帖用户的性别比例,可视化结果见example\count_gender.png
绘制关系图,每个topic对应的关系用户,用图谱的方式显示出来,结果见example\graph.html,本地双击用浏览器打开即可。可直接用graph.py代码生成
plot_id.py绘制的某帖图片
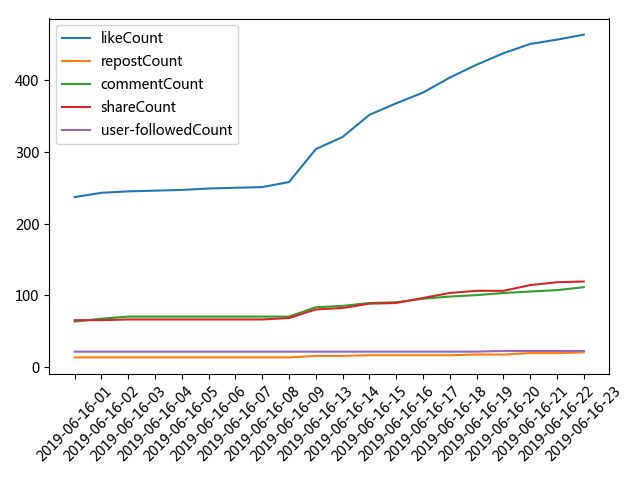
count_title.py绘制的随日期变化的topic关注人数变化图
get_map_data.py提取的数据,根据高德开放平台绘制的热力图
- 如果有运行错误或者不能理解的地方欢迎提issue
- 如果你有好的idea想要跟我分享也欢迎提issue或者直接发邮件至[email protected]
- 数据并不完全开放,如有定制需求或商业合作(包括不局限于爬虫、数据分析与挖掘、开发等),请直接发邮件[email protected]
本项目仅供交流学习